What is this PR for?
The goal of this PR is to be able to execute Spark notebooks on Kubernetes in cluster mode, so that the Spark Driver runs inside Kubernetes cluster - based on https://github.com/apache-spark-on-k8s/spark. Zeppelin uses spark-submit to start RemoteInterpreterServer which is able to execute notebooks on Spark. Kubernetes specific spark-submit parameters like driver, executor, init container, shuffle images should be set in SPARK_SUBMIT_OPTIONS environment variable. In case the Spark interpreter is configured with a K8 Spark specific master url (k8s://https....) RemoteInterpreterServer is launched inside a Spark driver pod on Kubernetes, thus Zeppelin server it has to be able to connect to the remote server. In a Kubernetes cluster the best solution for this is creating a K8S service for RemoteInterpreterServer. This is the reason for having the SparkK8RemoteInterpreterManagerProcess - extending functionality of RemoteInterpreterManagerProcess - which creates the Kubernetes service, mapping the port of RemoteInterpreterServer in Driver pod and connects to this service once Spark Driver pod is in Running state.
Design considerations: As described in spark-interpreter-k8s.md, the Zeppelin Server is running inside the Kubenetes cluster - thus we can choose where to run the Zeppelin server - the benefit of running the server inside K8S is that we don't have to deal with authentication. However is not enough to start only the Zeppelin Server inside the Kubernetes cluster as by default Zeppelin will start spark-submit in the same pod and will run every Spark job locally. The scope of this PR is run to run spark-submit (apache-spark-on-k8s version) properly configured with Docker images etc. so that the Spark driver will be started in a separate pod in the cluster, also staring separate pods for Spark executors thus we can benefit from dynamic scaling of executors inside the Kubernetes cluster (while all the scheduling, pod allocation, resource management is done by the Kubernetes scheduler).
Please see below how is this running/used:
The cluster:

The flow:

What type of PR is it?
Feature
What is the Jira issue?
- https://issues.apache.org/jira/browse/ZEPPELIN-3020
How should this be tested?
Unit and functional tests - running notebooks on Spark on K8S.
Questions:
- Does the licenses files need update?
- Is there breaking changes for older versions?
- Does this needs documentation?

![R and SparkR Support [WIP]](https://avatars.githubusercontent.com/u/226720?v=4)

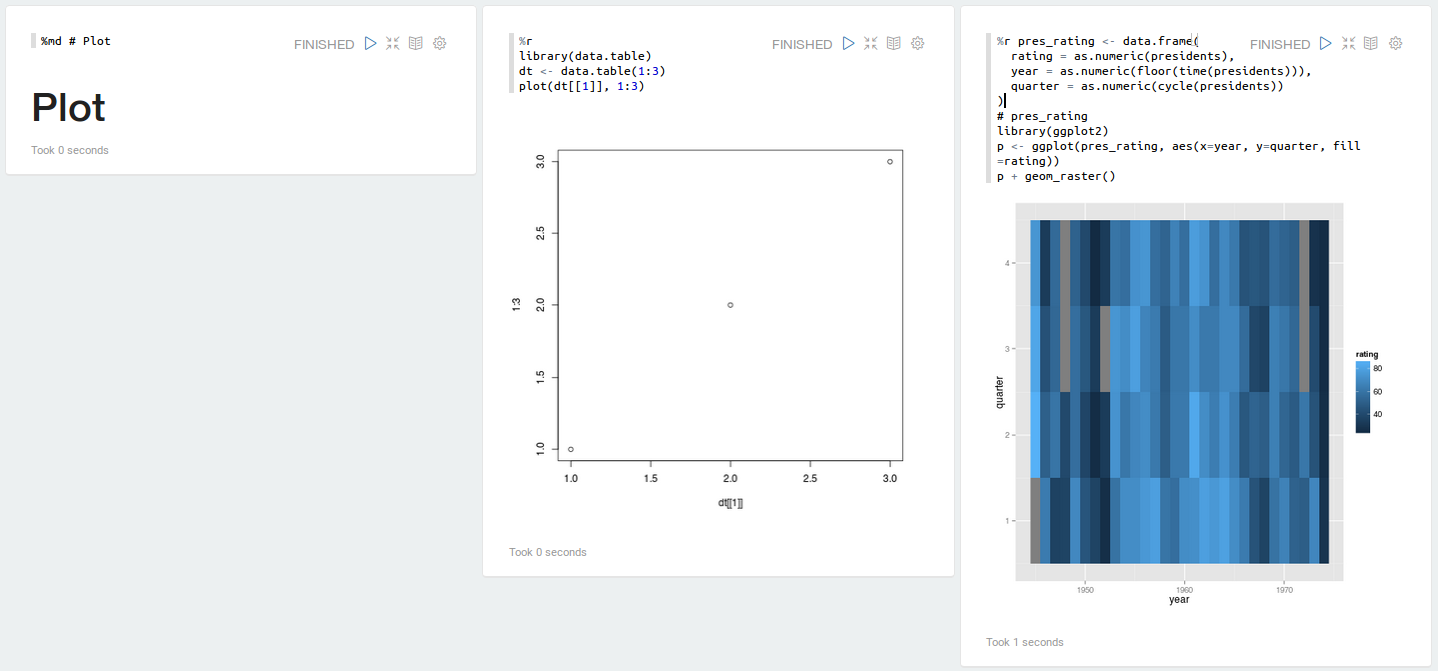
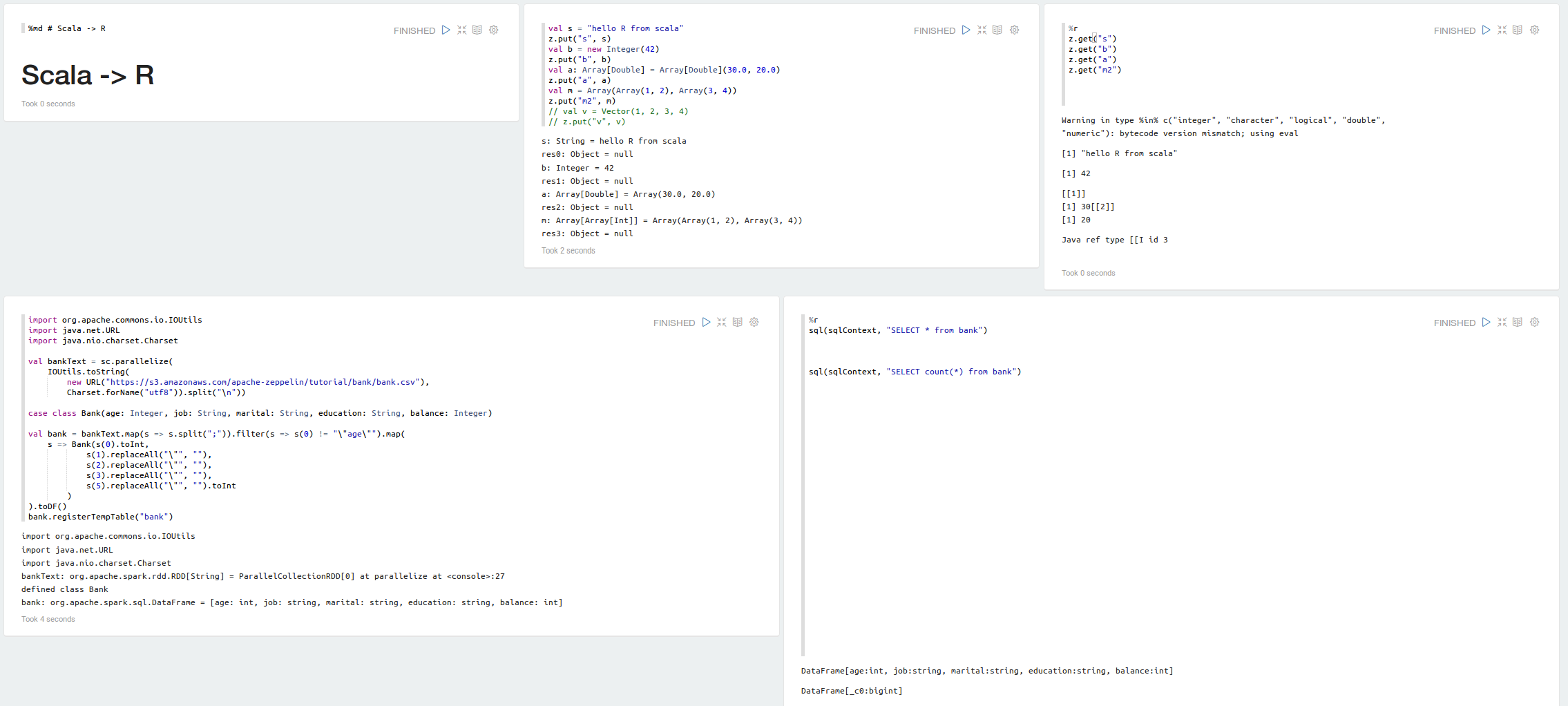

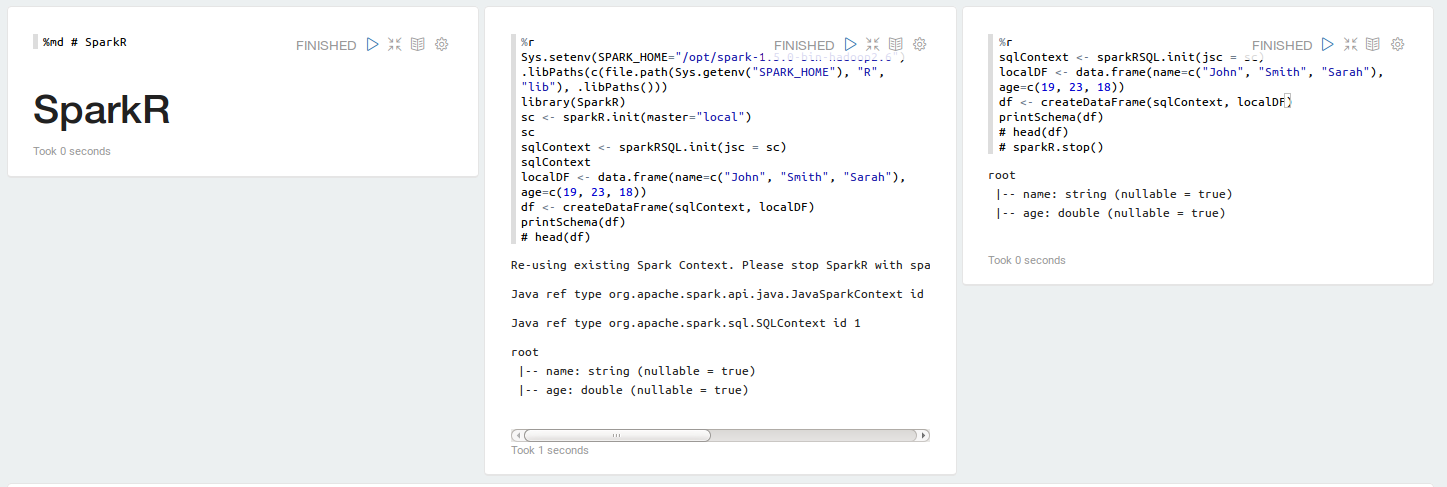
![[ZEPPELIN-116] Add Apache Mahout Interpreter](https://avatars.githubusercontent.com/u/5852441?v=4)


![[ZEPPELIN-2598] Securing Zeppelin with OpenID Connect](https://avatars.githubusercontent.com/u/5792097?v=4)
![[ZEPPELIN-1210] Run interpreter per user](https://avatars.githubusercontent.com/u/3612566?v=4)
![ZEPPELIN-672] Add Datatables instead of normal tables](https://avatars.githubusercontent.com/u/1140475?v=4)

![[ZEPPELIN-2582][DOCS] docs for interpreter binding modes](https://avatars.githubusercontent.com/u/4968473?v=4)




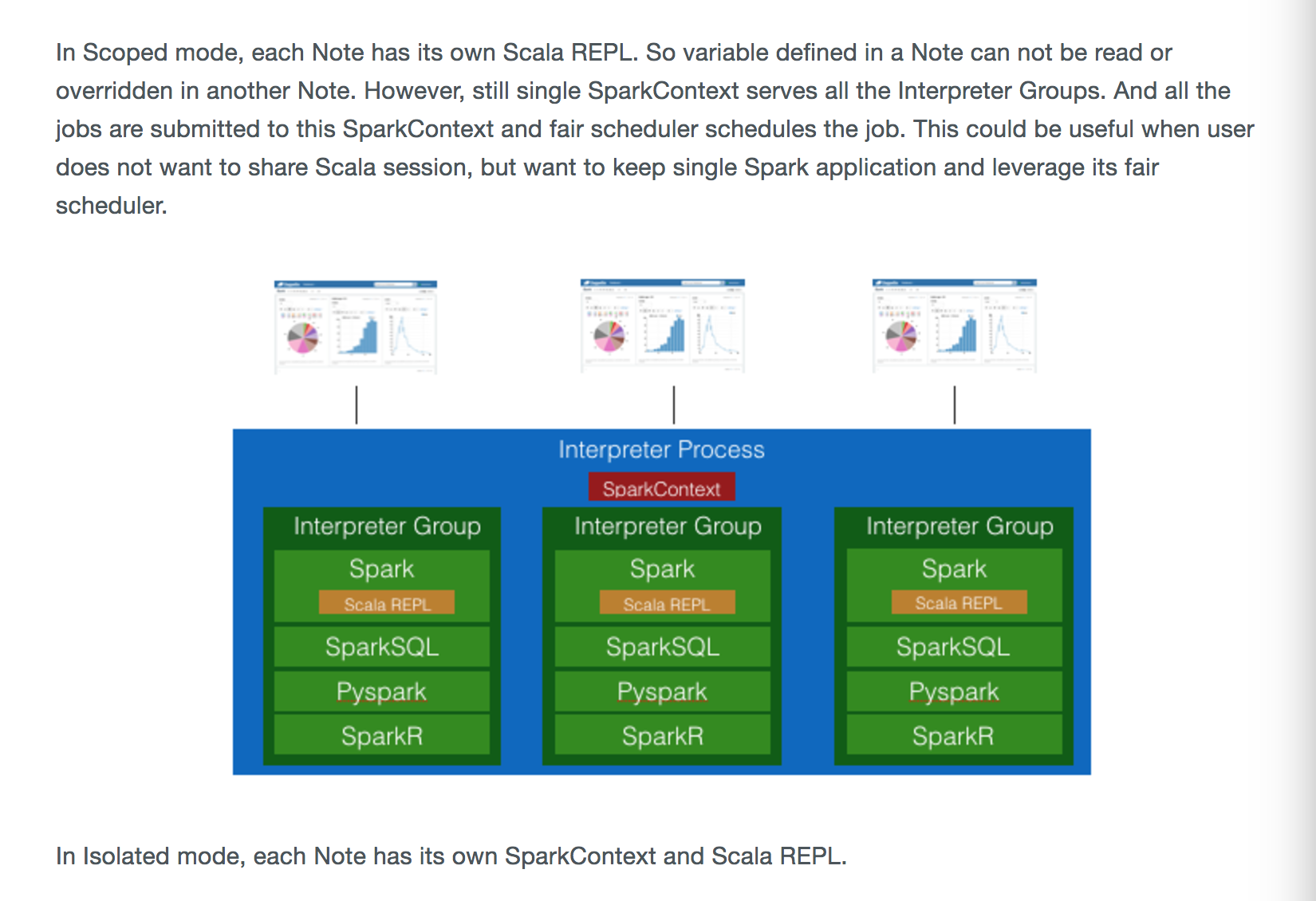

![[ZEPPELIN-707]Automatically adds %.* of previous paragraph's typing](https://avatars.githubusercontent.com/u/10624086?v=4)







 12.3k Jan 9, 2023
12.3k Jan 9, 2023
 14.3k Jan 5, 2023
14.3k Jan 5, 2023
 776 Jan 2, 2023
776 Jan 2, 2023
 8.9k Dec 26, 2022
8.9k Dec 26, 2022
 9.2k Jan 1, 2023
9.2k Jan 1, 2023
 1.2k Dec 31, 2022
1.2k Dec 31, 2022
 772 Dec 9, 2022
772 Dec 9, 2022
 589 Apr 1, 2022
589 Apr 1, 2022
 424 Dec 28, 2022
424 Dec 28, 2022
 3 Aug 23, 2021
3 Aug 23, 2021
 1 Jan 19, 2022
1 Jan 19, 2022
 2.2k Dec 30, 2022
2.2k Dec 30, 2022
 1.5k Dec 15, 2022
1.5k Dec 15, 2022
 583 Nov 11, 2022
583 Nov 11, 2022
 303 Dec 29, 2022
303 Dec 29, 2022
 5 Dec 19, 2021
5 Dec 19, 2021
 2 Feb 10, 2022
2 Feb 10, 2022
 962 Dec 31, 2022
962 Dec 31, 2022