Apache Lucene
Apache Lucene is a high-performance, full featured text search engine library written in Java.
Online Documentation
This README file only contains basic setup instructions. For more comprehensive documentation, visit:
Building with Gradle
Basic steps:
- Install OpenJDK 11 (or greater)
- Download Lucene from Apache and unpack it (or clone the git repository).
- Run gradle launcher script (
gradlew).
Step 0) Set up your development environment (OpenJDK 11 or greater)
We'll assume that you know how to get and set up the JDK - if you don't, then we suggest starting at https://jdk.java.net/ and learning more about Java, before returning to this README. Lucene runs with Java 11 or later.
Lucene uses Gradle for build control.
NOTE: Lucene changed from Ant to Gradle as of release 9.0. Prior releases still use Ant.
Step 1) Checkout/Download Lucene source code
You can clone the source code from GitHub:
https://github.com/apache/lucene
or get Lucene source archives for a particular release from:
https://lucene.apache.org/core/downloads.html
Download either a zip or a tarred/gzipped version of the archive, and uncompress it into a directory of your choice.
Step 2) Run Gradle
Run "./gradlew help", this will show the main tasks that can be executed to show help sub-topics.
If you want to build Lucene, type:
./gradlew assemble
NOTE: DO NOT use gradle command that is already installed on your machine (unless you know what you'll do). The "gradle wrapper" (gradlew) does the job - downloads the correct version of it, setups necessary configurations.
The first time you run Gradle, it will create a file "gradle.properties" that contains machine-specific settings. Normally you can use this file as-is, but it can be modified if necessary.
./gradlew check will assemble Lucene and run all validation tasks (including unit tests).
./gradlew help will print a list of help guides that help understand how the build and typical workflow works.
If you want to build the documentation, type:
./gradlew documentation
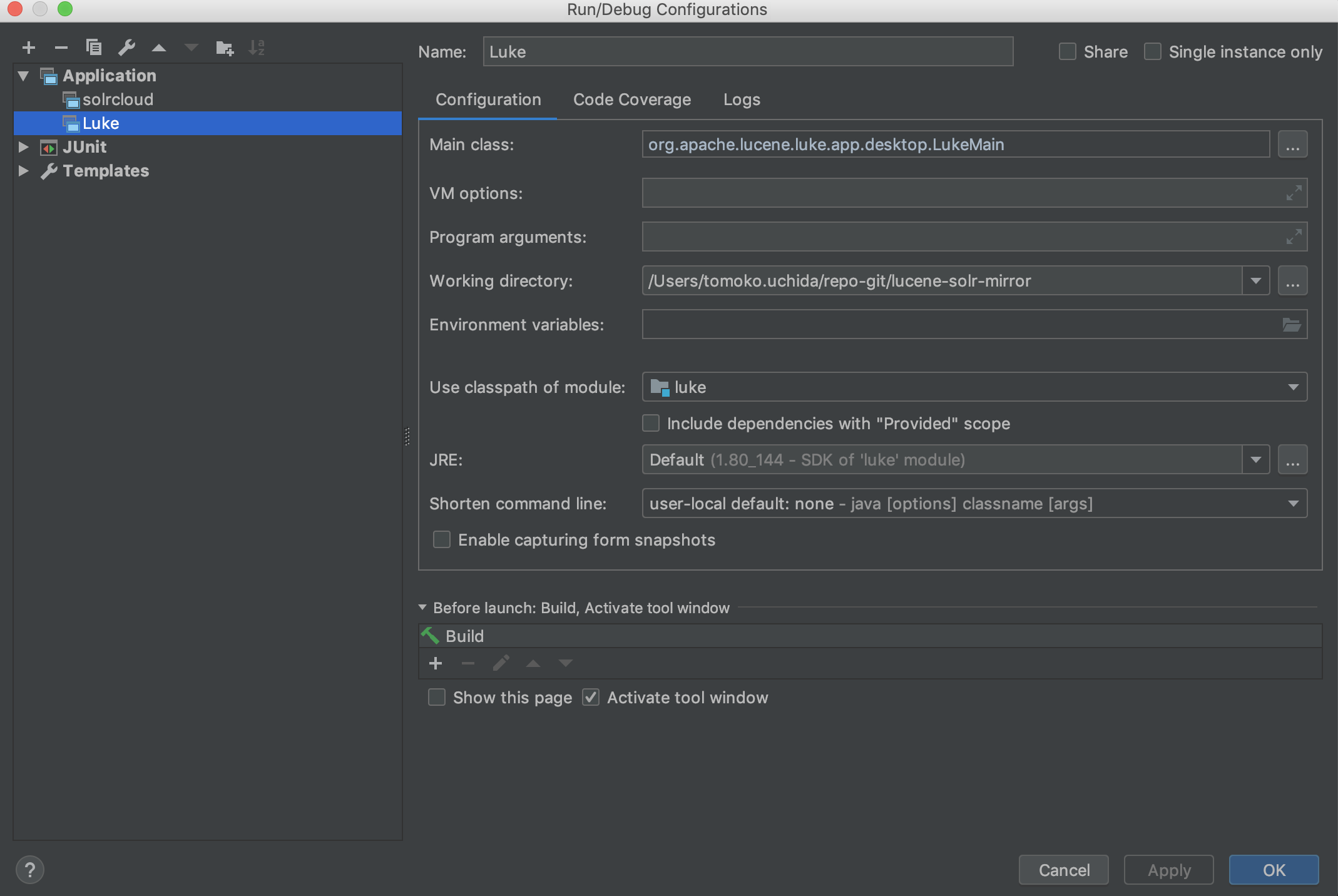
Gradle build and IDE support
- IntelliJ - IntelliJ idea can import the project out of the box.
- Eclipse - Basic support (help/IDEs.txt).
- Netbeans - Not tested.
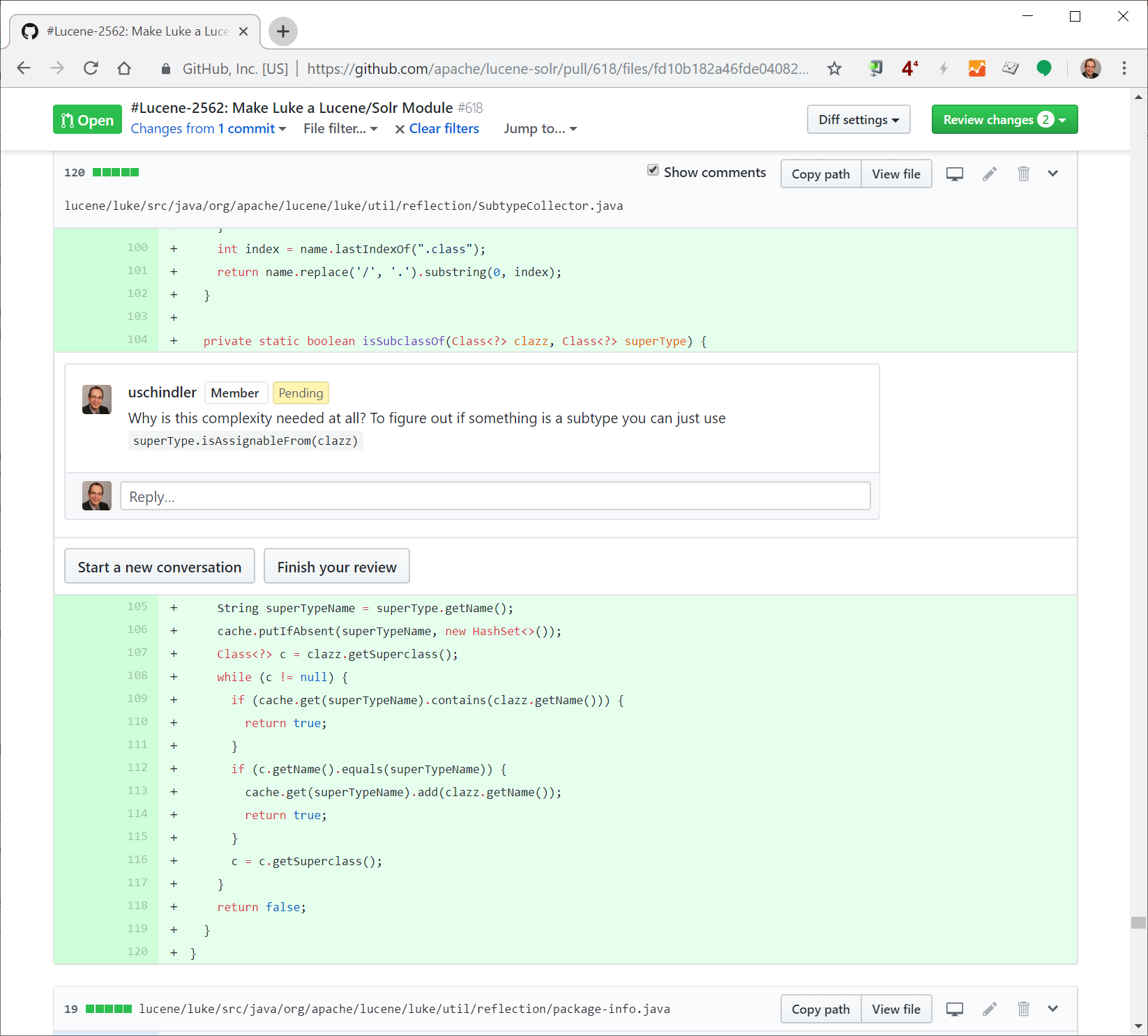
Contributing
Please review the Contributing to Lucene Guide for information on contributing.
Discussion and Support
- Users Mailing List
- Developers Mailing List
- Issue Tracker
- IRC:
#luceneand#lucene-devon freenode.net
![Change IndexSearcher multisegment searches to search each individual segment using a single HitCollector [LUCENE-1483]](https://avatars.githubusercontent.com/u/111339463?v=4)







 630 Dec 28, 2022
630 Dec 28, 2022
 6 Oct 24, 2022
6 Oct 24, 2022
 47 May 18, 2022
47 May 18, 2022
 62.3k Dec 31, 2022
62.3k Dec 31, 2022
 68 Nov 25, 2022
68 Nov 25, 2022
 6.2k Jan 1, 2023
6.2k Jan 1, 2023
 32 Sep 14, 2022
32 Sep 14, 2022
 350 Dec 30, 2022
350 Dec 30, 2022
 38 Oct 29, 2022
38 Oct 29, 2022
 4.5k Dec 30, 2022
4.5k Dec 30, 2022
 11 Oct 20, 2022
11 Oct 20, 2022
 5 Dec 4, 2021
5 Dec 4, 2021
 5k Jan 4, 2023
5k Jan 4, 2023
 32 Jul 4, 2022
32 Jul 4, 2022
 56 Dec 19, 2022
56 Dec 19, 2022
 821 Dec 17, 2022
821 Dec 17, 2022
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}