Apache Druid 0.22.0 contains over 400 new features, bug fixes, performance enhancements, documentation improvements, and additional test coverage from 73 contributors. See the complete set of changes for additional details.
# New features
# Query engine
# Support for multiple distinct aggregators in same query
Druid now can support multiple DISTINCT 'exact' counts using the grouping aggregator typically used with grouping sets. Note that this only applies to exact counts - when druid.sql.planner.useApproximateCountDistinct is false, and can be enabled by setting druid.sql.planner.useGroupingSetForExactDistinct to true.
https://github.com/apache/druid/pull/11014
# SQL ARRAY_AGG and STRING_AGG aggregator functions
The ARRAY_AGG aggregation function has been added, to allow accumulating values or distinct values of a column into a single array result. This release also adds STRING_AGG, which is similar to ARRAY_AGG, except it joins the array values into a single string with a supplied 'delimiter' and it ignores null values. Both of these functions accept a maximum size parameter to control maximum result size, and will fail if this value is exceeded. See SQL documentation for additional details.
https://github.com/apache/druid/pull/11157
https://github.com/apache/druid/pull/11241
# Bitwise math function expressions and aggregators
Several new SQL functions functions for performing 'bitwise' math (along with corresponding native expressions), including BITWISE_AND, BITWISE_OR, BITWISE_XOR and so on. Additionally, aggregation functions BIT_AND, BIT_OR, and BIT_XOR have been added to accumulate values in a column with the corresponding bitwise function. For complete details see SQL documentation.
https://github.com/apache/druid/pull/10605
https://github.com/apache/druid/pull/10823
https://github.com/apache/druid/pull/11280
# Human readable number format functions
Three new SQL and native expression number format functions have been added in Druid 0.22.0, HUMAN_READABLE_BINARY_BYTE_FORMAT, HUMAN_READABLE_DECIMAL_BYTE_FORMAT, and HUMAN_READABLE_DECIMAL_FORMAT, which allow transforming results into a more friendly consumption format for query results. For more information see SQL documentation.
https://github.com/apache/druid/issues/10584
https://github.com/apache/druid/pull/10635
# Expression aggregator
Druid 0.22.0 adds a new 'native' JSON query expression aggregator function, that lets you use Druid native expressions to perform "fold" (alternatively known as "reduce") operations to accumulate some value on any number of input columns. This adds significant flexibility to what can be done in a Druid aggregator, similar in a lot of ways to what was possible with the Javascript aggregator, but in a much safer, sandboxed manner.
Expressions now being able to perform a "fold" on input columns also really rounds out the abilities of native expressions in addition to the previously possible "map" (expression virtual columns), "filter" (expression filters) and post-transform (expression post-aggregators) functions.
Since this uses expressions, performance is not yet optimal, and it is not directly documented yet, but it is the underlying technology behind the SQL ARRAY_AGG, STRING_AGG, and bitwise aggregator functions also added in this release.
https://github.com/apache/druid/pull/11104
# SQL query routing improvements
Druid 0.22 adds some new facilities to provide extension writers with enhanced control over how queries are routed between Druid routers and brokers. The first adds a new manual broker selection strategy to the Druid router, which allows a query to manually specify which Druid brokers a query should be sent to based on a query context parameter brokerService to any broker pool defined in druid.router.tierToBrokerMap (this corresponds to the 'service name' of the broker set, druid.service).
The second new feature allows the Druid router to parse and examine SQL queries so that broker selection strategies can also function for SQL queries. This can be enabled by setting druid.router.sql.enable to true. This does not affect JDBC queries, which use a different mechanism to facilitate "sticky" connections to a single broker.
https://github.com/apache/druid/pull/11566
https://github.com/apache/druid/pull/11495
# Avatica protobuf JDBC Support
Druid now supports using Avatica Protobuf JDBC connections, such as for use with the Avatica Golang Driver, and has a separate endpoint from the JSON JDBC uri.
String url = "jdbc:avatica:remote:url=http://localhost:8082/druid/v2/sql/avatica-protobuf/;serialization=protobuf";
https://github.com/apache/druid/pull/10543
# Improved query error logging
Query exceptions have been changed from WARN level to ERROR level to include additional information in the logs to help troubleshoot query failures. Additionally, a new query context flag, enableQueryDebugging has been added that will include stack traces in these query error logs, to provide even more information without the need to enable logs at the DEBUG level.
https://github.com/apache/druid/pull/11519
# Streaming Ingestion
# Task autoscaling for Kafka and Kinesis streaming ingestion
Druid 0.22.0 now offers experimental support for dynamic Kafka and Kinesis task scaling. The included strategies are driven by periodic measurement of stream lag (which is based on message count for Kafka, and difference of age between the message iterator and the oldest message for Kinesis), and will adjust the number of tasks based on the amount of 'lag' and several configuration parameters. See Kafka and Kinesis documentation for complete information.
https://github.com/apache/druid/pull/10524
https://github.com/apache/druid/pull/10985
# Avro and Protobuf streaming InputFormat and Confluent Schema Registry Support
Druid streaming ingestion now has support for Avro and Protobuf in the updated InputFormat specification format, which replaces the deprecated firehose/parser specification used by legacy Druid streaming formats. Alongside this, comes support for obtaining schemas for these formats from Confluent Schema Registry. See data formats documentation for further information.
https://github.com/apache/druid/pull/11040
https://github.com/apache/druid/pull/11018
https://github.com/apache/druid/pull/10314
https://github.com/apache/druid/pull/10839
# Kafka ingestion support for specifying group.id
Druid Kafka streaming ingestion now optionally supports specifying group.id on the connections Druid tasks make to the Kafka brokers. This is useful for accessing clusters which require this be set as part of authorization, and can be specified in the consumerProperties section of the Kafka supervisor spec. See Kafka ingestion documentation for more details.
https://github.com/apache/druid/pull/11147
# Native Batch Ingestion
# Support for using deep storage for intermediary shuffle data
Druid native 'perfect rollup' 2-phase ingestion tasks now support using deep storage as a shuffle location, as an alternative to local disks on middle-managers or indexers. To use this feature, set druid.processing.intermediaryData.storage.type to deepstore, which uses the configured deep storage type.
Note - With "deepstore" type, data is stored in shuffle-data directory under the configured deep storage path, auto clean up for this directory is not supported yet. One can setup cloud storage lifecycle rules for auto clean up of data at shuffle-data prefix location.
https://github.com/apache/druid/pull/11507
# Improved native batch ingestion task memory usage
Druid native batch ingestion has received a new configuration option, druid.indexer.task.batchProcessingMode which introduces two new operating modes that should allow batch ingestion to operate with a smaller and more predictable heap memory usage footprint. The CLOSED_SEGMENTS_SINKS mode is the most aggressive, and should have the smallest memory footprint, and works by eliminating in memory tracking and mmap of intermediary segments produced during segment creation, but isn't super well tested at this point so considered experimental. CLOSED_SEGMENTS, which is the new default option, eliminates mmap of intermediary segments, but still tracks the entire set of segments in heap, though it is relatively well tested at this point and considered stable. OPEN_SEGMENTS will use the previous ingestion path, which is shared with streaming ingestion and performs a mmap on intermediary segments and builds a timeline so that these segments can be queryable by realtime queries. This is not needed at all for batch, but OPEN_SEGMENTS mode can be selected if any problems occur with the 2 newer modes.
https://github.com/apache/druid/pull/11123
https://github.com/apache/druid/pull/11294
https://github.com/apache/druid/pull/11536
# Allow batch tasks to wait until segment handoff before completion
Druid native batch ingestion tasks can now be optionally configured to not terminate until after the ingested segments are completely loaded by Historical servers. This can be useful for scenarios when the trade-off of keeping an extra task slot occupied is worth using the task state as a measure of if ingestion is complete and segments are available to query.
This can be enabled by adding awaitSegmentAvailabilityTimeoutMillis to the tuningConfig in the ingestion spec, which specifies the maximum amount of time that a task will wait for segments to be loaded before terminating. If not all segments become available by the time this timeout expires, the job will still succeed. However, in the ingestion report, segmentAvailabilityConfirmed will be false. This indicates that handoff was not successful and these newly indexed segments may not all be available for query. On the other hand, if all segments become available for query on the Historical services before the timeout expires, the value for that key in the report will be true.
This tuningConfig value is not supported for compaction tasks at this time. If a user tries to specify a value for awaitSegmentAvailabilityTimeoutMillis for Compaction, the task will fail telling the user it is not supported.
https://github.com/apache/druid/pull/10676
# Data lifecycle management
# Support managing segment and query granularity for auto-compaction
Druid manual and automatic compaction can now be configured to change segment granularity, and manual compaction can also change query granularity. Additionally, compaction will preserve segment granularity by default. This allows operators to more easily perform options like changing older data to larger segment and query granularities in exchange for decreased data size. See compaction docs for details.
https://github.com/apache/druid/pull/10843
https://github.com/apache/druid/pull/10856
https://github.com/apache/druid/pull/10900
https://github.com/apache/druid/pull/10912
https://github.com/apache/druid/pull/11009
# Allow compaction to temporarily skip locked intervals
Druid auto-compaction will now by default temporarily skip locked intervals instead of waiting for the lock to become free, which should improve the rate at which datasources can be compacted. This is controlled by druid.coordinator.compaction.skipLockedIntervals, and can be set to false if this behavior is not desired for some reason.
https://github.com/apache/druid/pull/11190
# Support for additional automatic metadata cleanup
You can configure automated cleanup to remove records from the metadata store after you delete delete some entities from Druid:
- segments records
- audit records
- supervisor records
- rule records
- compaction configuration records
- datasource records created by supervisors
This feature helps maintain performance when you have a high datasource churn rate, meaning you frequently create and delete many short-lived datasources or other related entities. You can limit the length of time to retain unused metadata records to prevent your metadata store from filling up. See automatic cleanup documentation for more information.
https://github.com/apache/druid/pull/11078
https://github.com/apache/druid/pull/11084
https://github.com/apache/druid/pull/11164
https://github.com/apache/druid/pull/11200
https://github.com/apache/druid/pull/11227
https://github.com/apache/druid/pull/11232
https://github.com/apache/druid/pull/11245
# Dropping data
A new setting, dropExisting has been added to the ioConfig of Druid native batch ingestion tasks and compaction, which if set to true (and appendToExist is false), then the ingestion task will transactionally mark all existing segments in the interval as unused, replacing them with the new set of segments. This can be useful in compaction use cases where normal overshadowing does not completely replace a set of segments in an interval, such as when changing segment granularity to a smaller size and some of the smaller granularity buckets would have no data, leaving the original segments only partially overshadowed.
Note that this functionality is still experimental, and can result in temporary data unavailability for data within the compacted interval. Changing this config does not cause intervals to be compacted again.
Similarly, markAsUnused has been added as an option to the Druid kill task, which will mark any segments in the supplied interval as 'unused' prior to deleting all of the unused segments. This is useful for allowing the mark unused -> delete sequence to happen with a single API call for the caller, as well as allowing the unmark action to occur under a task interval lock.
https://github.com/apache/druid/pull/11070
https://github.com/apache/druid/pull/11025
https://github.com/apache/druid/pull/11501
# Coordinator
# Control over coordinator segment load timeout timeout behavior with Apache Zookeeper based segment management
A new Druid coordinator dynamic configuration option allows controlling the behavior whenever a segment load action times out when using Zookeeper based segment management. replicateAfterLoadTimeout when set to true, the coordinator will attempt to replicate the segment that failed to load to a different historical server. This helps improve the segment availability if there are a few slow historical servers in the cluster. However, the slow historical may still load the segment later and the coordinator may need to issue drop requests if the segment is over-replicated.
https://github.com/apache/druid/pull/10213
# Faster coordinator segment balancing
Another new coordinator dynamic configuration option, useBatchedSegmentSampler, when set to true can potentially provide a large performance increase in the speed which the coordinator can process the segment balancing phase. This should be particularly notable at very large cluster sizes with many segments, but is disabled by default to err on the side of caution.
https://github.com/apache/druid/pull/11257
# Improved loadstatus API to optionally compute under-replication based on cluster size
The Druid coordinator load status API now supports a new optional URL query parameter, computeUsingClusterView, which when specified will cause the coordinator compute under-replication for segments based on the number of servers available within cluster that the segment can be replicated to, instead of the configured replication count configured in load rule. For example, if the load rules specify 2 replicas, but there is only 1 server which can hold segments, this API would not report as under-replicated because the segments are as replicated as is possible for the given cluster size.
https://github.com/apache/druid/pull/11056
# Optional limits on the number of non-primary replicants loaded per coordination cycle
A new coordinator dynamic configuration, maxNonPrimaryReplicantsToLoad, with default value of Integer.MAX_VALUE, lets operators to define a hard upper limit on the number of non-primary replicants that will be loaded in a single coordinator execution cycle. The default value will mimic the behavior that exists today.
Example usage: If you set this configuration to 1000, the coordinator will load a maximum of 1000 non-primary replicants in each run cycle execution. Meaning if you ingested 2000 segments with a replication factor of 2, the coordinator would load 2000 primary replicants and 1000 non-primary replicants on the first execution. Then the next execution, the last 1000 non-primary replicants will be loaded.
https://github.com/apache/druid/pull/11135
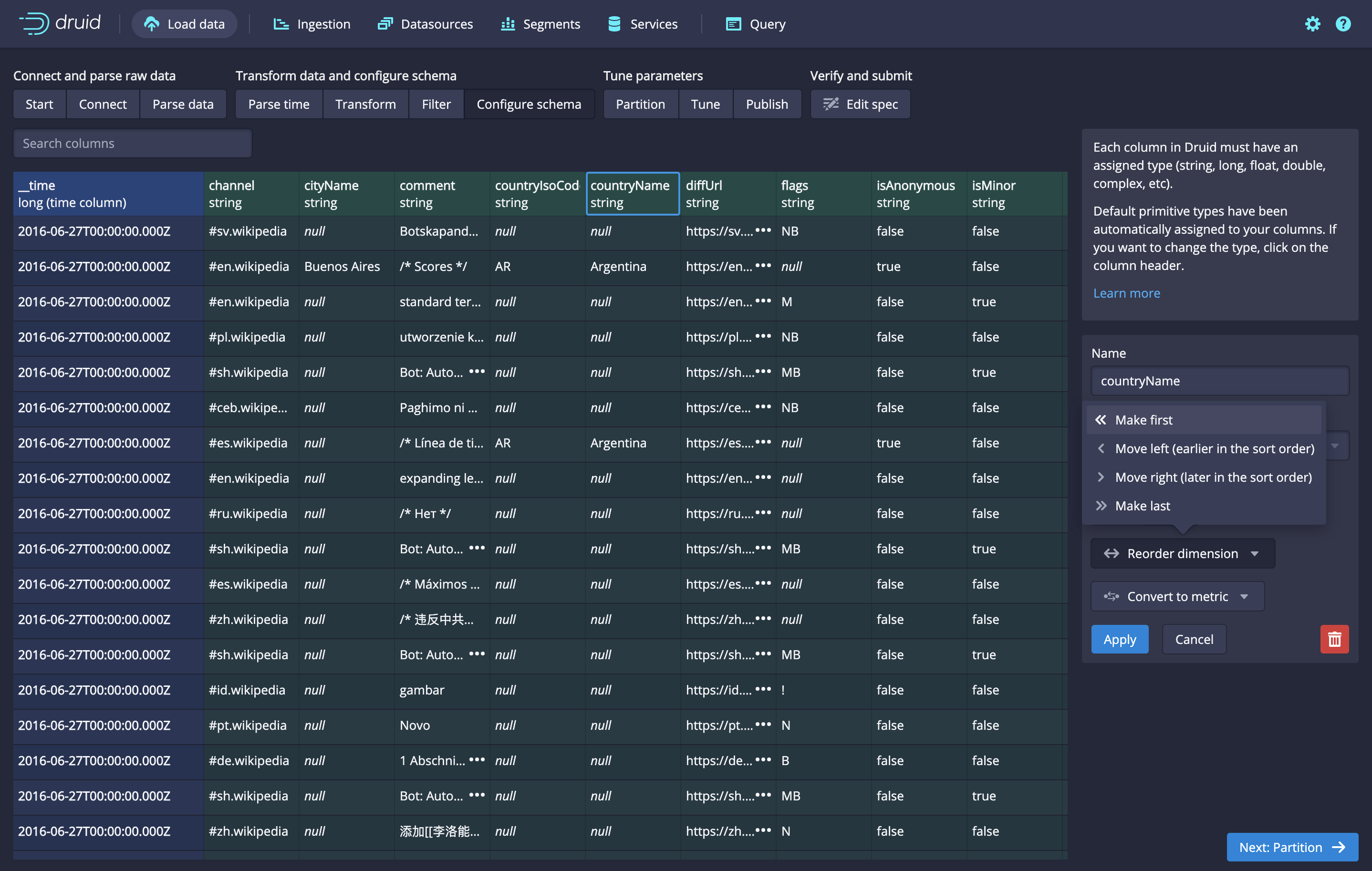
# Web Console
# General improvements
The Druid web-console 'services' tab will now display which coordinator and overlord servers are serving as the leader, displayed in the 'Detail' column of the table. This should help operators be able to more quickly determine which node is the leader and thus which likely has the interesting logs to examine.
The web-console now also supports using ASCII control characters, by entering them in the form of \uNNNN where NNNN is the unicode code point for the character.
https://github.com/apache/druid/pull/10951
https://github.com/apache/druid/pull/10795
# Query view
The query view of the web-console has received a number of 'quality of life' improvements in Druid 0.22.0. First, the query view now provides an indicator of how long a query took to execute:

Also, queries will no longer auto-run when opening a fresh page, to prevent stale queries from being executed when opening a browser, the page will be reset to 0 if the query result changes and the query limit will automatically increase when the last page is loaded re-running the query.
Inline documentation now also should include Druid type information:
 and should provide better suggestions whenever a query error occurs:
and should provide better suggestions whenever a query error occurs:

Finally, the web console query view now supports the hot-key combination command + enter (on mac) and ctrl + enter on Windows and Linux.
https://github.com/apache/druid/pull/11158
https://github.com/apache/druid/pull/11128
https://github.com/apache/druid/pull/11203
https://github.com/apache/druid/pull/11365
# Data management
The web-console segments view timeline now has the ability to pick any time interval, instead of just the previous year!

The web-console segments view has also been improved to hopefully be more performant when interacting with the sys.segments table, including providing the ability to 'force' the web-console to only use the native JSON API methods to display segment information:

The lookup view has also been improved, so that now 'poll period' and 'summary' are available as columns in the list view:

We have also added validation for poll period to prevent user error, and improved error reporting:

https://github.com/apache/druid/pull/11359
https://github.com/apache/druid/pull/10909
https://github.com/apache/druid/pull/11620
# Metrics
# Prometheus metric emitter
A new "contrib" extension has been added, prometheus-emitter, which allows Druid metrics to be sent directly to a Prometheus server. See the extension documentation page for complete details: https://druid.apache.org/docs/0.22.0/development/extensions-contrib/prometheus.html
https://github.com/apache/druid/pull/10412
https://github.com/apache/druid/pull/11618
# ingest/notices/queueSize
ingest/notices/queueSize is a new metric added to provide monitoring for supervisor ingestion task control message processing queue sizes, to help in determining if a supervisor might be overloaded by a large volume of these notices. This metric is emitted by default for every running supervisor.
https://github.com/apache/druid/pull/11417
# query/segments/count
query/segments/count is a new metric which has been added to track the number of segments which participate in a query. This metric is not enabled by default, so must be enabled via a custom extension to override which QueryMetrics are emitted similar to other query metrics that are not emitted by default. (We know this is definitely not friendly, and hope someday in the future to make this easier, sorry).
https://github.com/apache/druid/pull/11394
# Cloud integrations
# AWS Web Identity / IRSA Support
Druid 0.22.0 adds AWS Web Identity Token Support, which allows for the use of IAM roles for service accounts on Kubernetes, if configured as the AWS credentials provider.
https://github.com/apache/druid/pull/10541
# S3 ingestion support for assuming a role
Druid native batch ingestion from S3 input sources can now use the AssumeRole capability in AWS for cross-account file access. This can be utilized by setting assumeRoleArn and assumeRoleExternalId on the S3 input source specification in a batch ingestion task. See AWS documentation and native batch documentation for more details.
https://github.com/apache/druid/pull/10995
# Google Cloud Storage support for URI lookups
Druid lookups now support loading via Google Cloud Storage, similar to existing functionality available with S3. This requires the druid-google-extensions must be loaded in addition to the lookup extensions, but beyond that it is as simple as using a Google Cloud Storage URI.
https://github.com/apache/druid/pull/11026
# Other changes
# Extracting Avro union fields by type
Avro ingestion using Druid batch or streaming ingestion now supports an alternative mechanism of extracting data for Avro Union types. This new option, extractUnionsByType only works when utilizing a flattenSpec to extract nested data from union types, and will cause the extracted data to be available with the type as part of the flatten path. For example, given a multi-typed union column someMultiMemberUnion, with this option enabled a long value would be extracted by $.someMultiMemberUnion.long instead of $.someMultiMemberUnion, and would only extract long values from the union. See Avro documentation for complete information.
https://github.com/apache/druid/pull/10505
# Support using MariaDb connector with MySQL extensions
Druid MySQL extensions now supports using the MariaDB connector library as an alternative to the MySQL connector. This can be done by setting druid.metadata.mysql.driver.driverClassName to org.mariadb.jdbc.Driver and includes full support for JDBC URI parameter whitelists used by JDBC lookups and SQL based ingestion.
https://github.com/apache/druid/pull/11402
# Add Environment Variable DynamicConfigProvider
Druid now provides a DynamicConfigProvider implementation that is backed by environment variables. For example:
druid.some.config.dynamicConfigProvider={"type": "environment","variables":{"secret1": "SECRET1_VAR","secret2": "SECRET2_VAR"}}
See dynamic config provider documentation for further information.
https://github.com/apache/druid/pull/11377
# Add DynamicConfigProvider for Schema Registry
Ingestion formats which support Confluent Schema Registry now support supplying these parameters via a DynamicConfigProvider which is the newer alternative to PasswordProvider. This will allow ingestion tasks to use the config provider to supply this information instead of directly in the JSON specifications, allowing the potential for more secure manners of supplying credentials and other sensitive configuration information. See data format and dynamic config provider documentation for more details.
https://github.com/apache/druid/pull/11362
# Security fixes
# Control of allowed protocols for HTTP and HDFS input sources
Druid 0.22.0 adds new facilities to control the set of allowed protocols used by HTTP and HDFS input sources in batch ingestion. druid.ingestion.hdfs.allowedProtocols is configured by default to accept hdfs as the protocol, and druid.ingestion.http.allowedProtocols by default will allow http and https. This might cause issue with existing deployments since it is more restrictive than the current default behavior in older versions of Druid, but overall allows operators more flexibility in securing these input sources.
https://github.com/apache/druid/pull/10830
# Fix expiration logic for LDAP internal credential cache
This version of Druid also fixes a flaw in druid-basic-security extension when using LDAP, where the credentials cache would not correctly expire, potentially holding expired credential information after it should have expired, until another trigger was hit or the service was restarted. Druid clusters using LDAP for authorization should update to 0.22.0 whenever possible to fix this issue.
https://github.com/apache/druid/pull/11395
# Performance improvements
# General performance
- improved granularity processing speed: https://github.com/apache/druid/pull/10904
- improved string comparison performance: https://github.com/apache/druid/pull/11171
# JOIN query enhacements
- improved performance for certain
JOIN queries by allowing some INNER JOIN queries to be translated into native Druid filters: https://github.com/apache/druid/pull/11068
- support filter pushdown into the left base table for certain
JOIN queries, controlled by new query context parameter enableJoinLeftTableScanDirect (default to false): https://github.com/apache/druid/pull/10697
# SQL
- improved SQL group by query performance by using native query granularity when possible: https://github.com/apache/druid/pull/11379
- added
druid.sql.avatica.minRowsPerFrame broker configuration which can be used to significantly improve JDBC performance by increasing the result batch size: https://github.com/apache/druid/pull/10880
- faster SQL parsing through improved expression parsing and exception handling: https://github.com/apache/druid/pull/11041
- improved query performance for
sys.segments: https://github.com/apache/druid/pull/11008
- reduced SQL schema lock contention on brokers: https://github.com/apache/druid/pull/11457
- improved performance of
segmentMetadata queries which are used to build SQL schema https://github.com/apache/druid/pull/10892
# Vectorized query engine
- vectorized query engine support for DataSketches quantiles aggregator: https://github.com/apache/druid/pull/11183
- vectorized query engine support for DataSketches theta sketch aggregator: https://github.com/apache/druid/pull/10767
- vectorized query engine support for Druid cardinality aggregator: https://github.com/apache/druid/pull/11182
- vectorization support has been added for expression filter: https://github.com/apache/druid/pull/10613
- vectorized group by support for string expressions: https://github.com/apache/druid/pull/11010
- deferred string expression evaluation support for vectorized group by engine: https://github.com/apache/druid/pull/11213
- improved column scan speed for
LONG columns with 'auto' encoding (not the default): https://github.com/apache/druid/pull/11004
- improved column scan/filtering speeds when contiguous blocks of values are read: https://github.com/apache/druid/pull/11039
# Bug fixes
Druid 0.22.0 contains over 80 bug fixes, you can see the complete list here.
# Upgrading to 0.22.0
Consider the following changes and updates when upgrading from Druid 0.21.x to 0.22.0. If you're updating from an earlier version than 0.21.0, see the release notes of the relevant intermediate versions.
# Dropped support for Apache ZooKeeper 3.4
Following up to 0.21, which officially deprecated support for Zookeeper 3.4, which has been end-of-life for a while, support for ZooKeeper 3.4 is now removed in 0.22.0. Be sure to upgrade your Zookeeper cluster prior to upgrading your Druid cluster to 0.22.0.
https://github.com/apache/druid/issues/10780
https://github.com/apache/druid/pull/11073
# Native batch ingestion segment allocation fix
Druid 0.22.0 includes an important bug-fix in native batch indexing where transient failures of indexing sub-tasks can result in non-contiguous partitions in the result segments, which will never become queryable due to logic which checks for the 'complete' set. This issue has been resolved in the latest version of Druid, but required a change in the protocol which batch tasks use to allocate segments, and this change can cause issues during rolling downgrades if you decide to roll back from Druid 0.22.0 to an earlier version.
To avoid task failure during a rolling-downgrade, set
druid.indexer.task.default.context={ "useLineageBasedSegmentAllocation" : false }
in the overlord runtime properties, and wait for all tasks which have useLineageBasedSegmentAllocation set to true to complete before initiating the downgrade. After these tasks have all completed the downgrade shouldn't have any further issue and the setting can be removed from the overlord configuration (recommended, as you will want this setting enabled if you are running Druid 0.22.0 or newer).
https://github.com/apache/druid/pull/11189
# SQL timeseries no longer skip empty buckets with all granularity
Prior to Druid 0.22, an SQL group by query which is using a single universal grouping key (e.g. only aggregators) such as SELECT COUNT(*), SUM(x) FROM y WHERE z = 'someval' would produce an empty result set instead of [0, null] that might be expected from this query matching no results. This was because underneath this would plan into a timeseries query with 'ALL' granularity, and skipEmptyBuckets set to true in the query context. This latter option caused the results of such a query to return no results, as there are no buckets with values to aggregate and so they are skipped, making an empty result set instead of a 'nil' result set. This behavior has been changed to behave in line with other SQL implementations, but the previous behavior can be obtained by explicitly setting skipEmptyBuckets on the query context.
https://github.com/apache/druid/pull/11188
# Druid reingestion incompatible changes
Batch tasks using a 'Druid' input source to reingest segment data will no longer accept the 'dimensions' and 'metrics' sections of their task spec, and now will internally use a new columns filter to specify which columns from the original segment should be retained. Additionally, timestampSpec is no longer ignored, allowing the __time column to be modified or replaced with a different column. These changes additionally fix a bug where transformed columns would be ignored and unavailable on the new segments.
https://github.com/apache/druid/pull/10267
# Druid web-console no longer supports IE11 and other older browsers
Some things might still work, but it is no longer officially supported so that newer Javascript features can be used to develop the web-console.
https://github.com/apache/druid/pull/11357
# Changed default maximum segment loading queue size
Druid coordinator maxSegmentsInNodeLoadingQueue dynamic configuration has been changed from unlimited (0) to instead to 100. This should make the coordinator behave in a much more relaxed manner during periods of cluster volatility, such as a rolling upgrade, but caps the total number of segments that will be loaded in any given coordinator cycle to 100 per server, which can slow down the speed at which a completely stopped cluster is started and loaded from deep storage.
https://github.com/apache/druid/pull/11540
# Developer notices
# CacheKeyBuilder moved from druid-processing to druid-core
The CacheKeyBuilder class, which is annotated with @PublicAPI has been moved from druid-processing to druid-core so that expressions can extend the Cacheable interface to allow expressions to generate cache keys which depend on some external state, such as lookup version.
https://github.com/apache/druid/pull/11358
# Query engine now uses new QueryProcessingPool instead of ExecutorService directly
This impacts a handful of method signatures in the query processing engine, such as QueryRunnerFactory and QuerySegmentWalker to allow extensions to hook into various parts of the query processing pool and alternative processing pool scheduling strategies in the future.
https://github.com/apache/druid/pull/11382
# SegmentLoader is now extensible and customizable
This allows extensions to provide alternative segment loading implementations to customize how Druid segments are loaded from deep storage and made available to the query engine. This should be considered an unstable api, and is annotated as such in the code.
https://github.com/apache/druid/pull/11398
# Known issues
For a full list of open issues, please see https://github.com/apache/druid/labels/Bug.
# Credits
Thanks to everyone who contributed to this release!
@2bethere
@a2l007
@abhishekagarwal87
@AKarbas
@AlexanderSaydakov
@ArvinZheng
@asdf2014
@astrohsy
@bananaaggle
@benkrug
@bergmt2000
@camteasdale143
@capistrant
@Caroline1000
@chenyuzhi459
@clintropolis
@cryptoe
@DaegiKim
@dependabot[bot]
@dkoepke
@dongjoon-hyun
@egor-ryashin
@fhan688
@FrankChen021
@gianm
@harinirajendran
@himadrisingh
@himanshug
@hqx871
@imply-jbalik
@imply-jhan
@isandeep41
@jasonk000
@jbampton
@jerryleooo
@jgoz
@jihoonson
@jon-wei
@josephglanville
@jp707049
@junegunn
@kaijianding
@kazuhirokomoda
@kfaraz
@lkm
@loquisgon
@MakDon
@maytasm
@misqos
@mprashanthsagar
@mSitkovets
@paul-rogers
@petermarshallio
@pjain1
@rohangarg
@samarthjain
@shankeerthan-kasilingam
@spinatelli
@sthetland
@suneet-s
@techdocsmith
@Tiaaa
@tushar-1728
@viatcheslavmogilevsky
@viongpanzi
@vogievetsky
@vtlim
@wjhypo
@wx930910
@xvrl
@yuanlihan
@zachjsh
@zhangyue19921010
Source code(tar.gz)
Source code(zip)








 Here is our traffic pattern. I have to set taskCount to 8, avoiding Kafka lag during traffic peak. At other times, 4 tasks are enough.
This PR provides the ability of auto scaling the number of Kafka ingest tasks based on Lag metrics when supervisors are running. Enable this feature and ingest tasks will auto scale out during traffic peak and scale in during traffic off-peak.
Here is our traffic pattern. I have to set taskCount to 8, avoiding Kafka lag during traffic peak. At other times, 4 tasks are enough.
This PR provides the ability of auto scaling the number of Kafka ingest tasks based on Lag metrics when supervisors are running. Enable this feature and ingest tasks will auto scale out during traffic peak and scale in during traffic off-peak.
 As the picture shows, SupervisorManger controls all the supervisors in OverLord Service. Each Kafka Supervisor serially consume notices in LinkedBlockingQueue. Notice is an interface. RunNotice, ShutdownNotice and RestNotice are implementations of this interface. I design a new implementation named DynamicAllocationTasksNotice. I create a new Timer(lagComputationExec) to collect Kafka lags at fix rate and create a new Timer(allocationExec) to check and do scale action at fix rate, as shown below
As the picture shows, SupervisorManger controls all the supervisors in OverLord Service. Each Kafka Supervisor serially consume notices in LinkedBlockingQueue. Notice is an interface. RunNotice, ShutdownNotice and RestNotice are implementations of this interface. I design a new implementation named DynamicAllocationTasksNotice. I create a new Timer(lagComputationExec) to collect Kafka lags at fix rate and create a new Timer(allocationExec) to check and do scale action at fix rate, as shown below
 For allocationExec details ,
For allocationExec details ,
 Furthermore, I expand the ioConfig spec and add new parameters to control the scale behave, for example
Furthermore, I expand the ioConfig spec and add new parameters to control the scale behave, for example






































 1.8k Dec 28, 2022
1.8k Dec 28, 2022
 27 Dec 28, 2022
27 Dec 28, 2022
 1.2k Dec 31, 2022
1.2k Dec 31, 2022
 5.9k Jan 8, 2023
5.9k Jan 8, 2023
 2k Dec 29, 2022
2k Dec 29, 2022
 589 Apr 1, 2022
589 Apr 1, 2022
 561 Dec 4, 2022
561 Dec 4, 2022
 19 Dec 12, 2022
19 Dec 12, 2022
 776 Jan 2, 2023
776 Jan 2, 2023
 6 Mar 23, 2022
6 Mar 23, 2022
 1.9k Dec 22, 2022
1.9k Dec 22, 2022
 566 Dec 22, 2022
566 Dec 22, 2022