Tablesaw


Overview
Tablesaw is Java for data science. It includes a dataframe and a visualization library, as well as utilities for loading, transforming, filtering, and summarizing data. It's fast and careful with memory. If you work with data in Java, it may save you time and effort. Tablesaw also supports descriptive statistics and integrates well with the Smile machine learning library.
Tablesaw features
Data processing & transformation
- Import data from RDBMS, Excel, CSV, JSON, HTML, or Fixed Width text files, whether they are local or remote (http, S3, etc.)
- Export data to CSV, JSON, HTML or Fixed Width files.
- Combine tables by appending or joining
- Add and remove columns or rows
- Sort, Group, Query
- Map/Reduce operations
- Handle missing values
Visualization
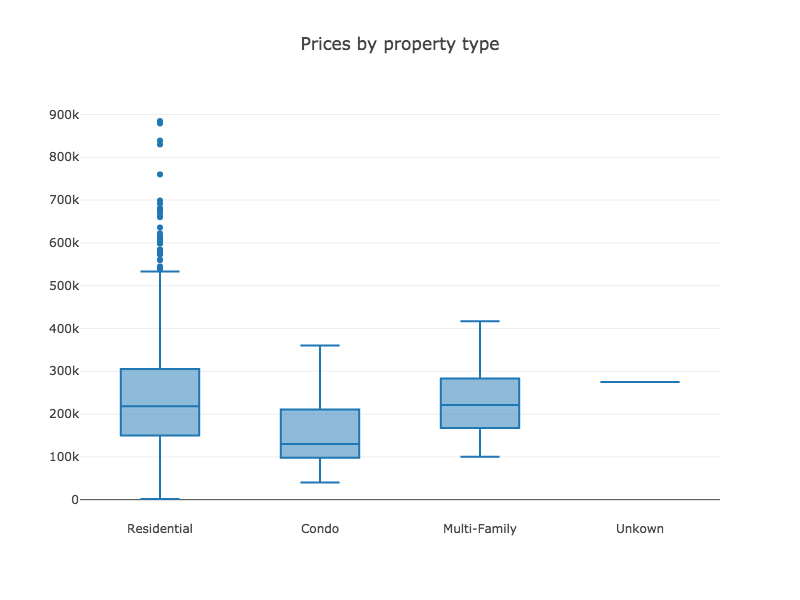
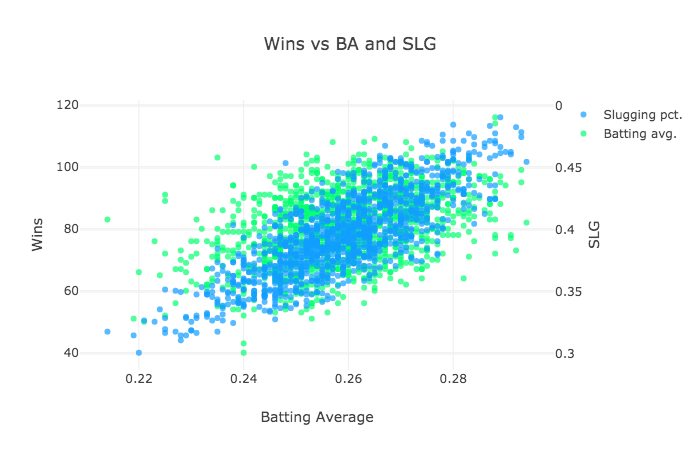
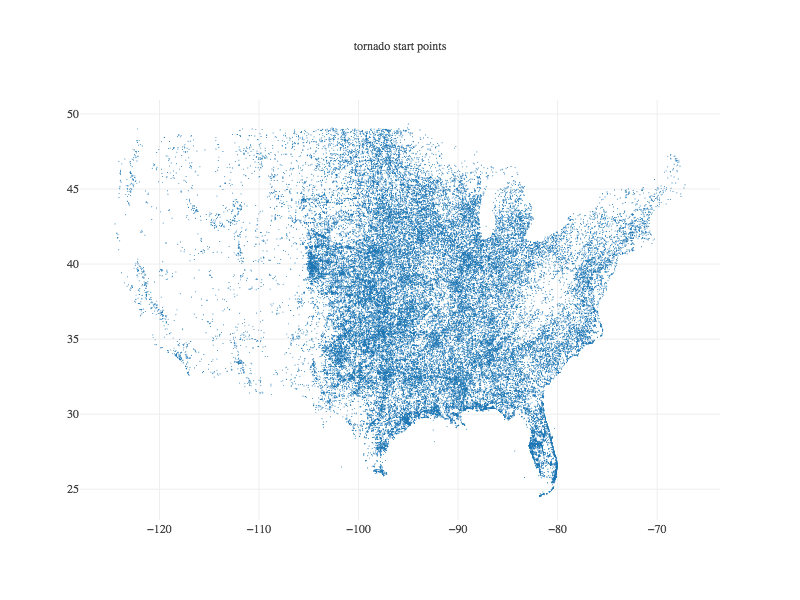
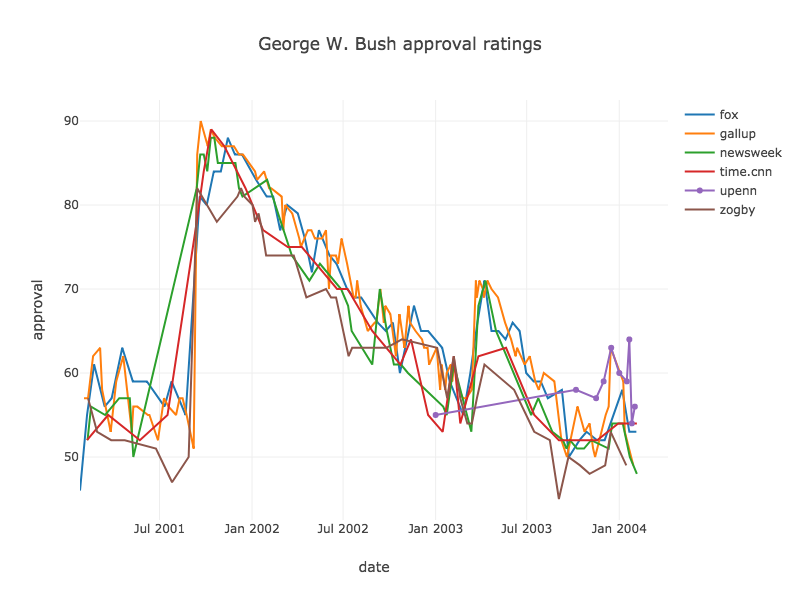
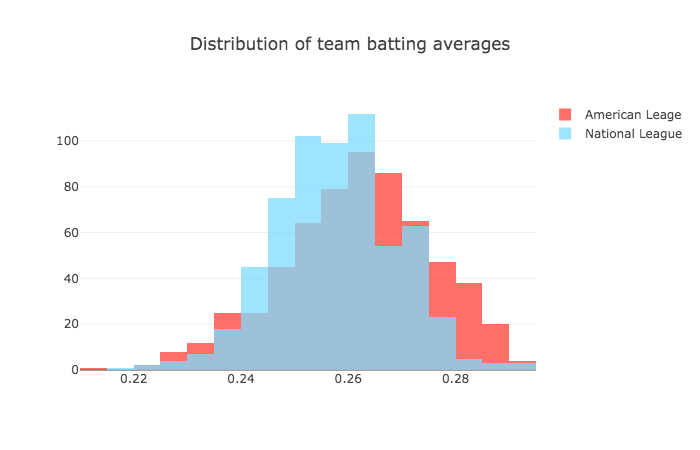
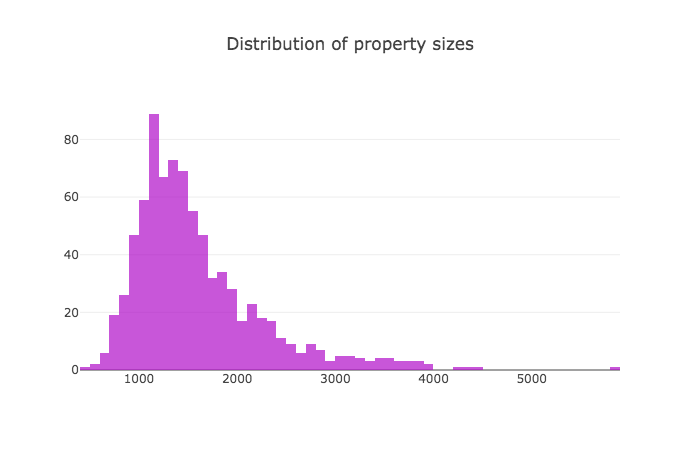
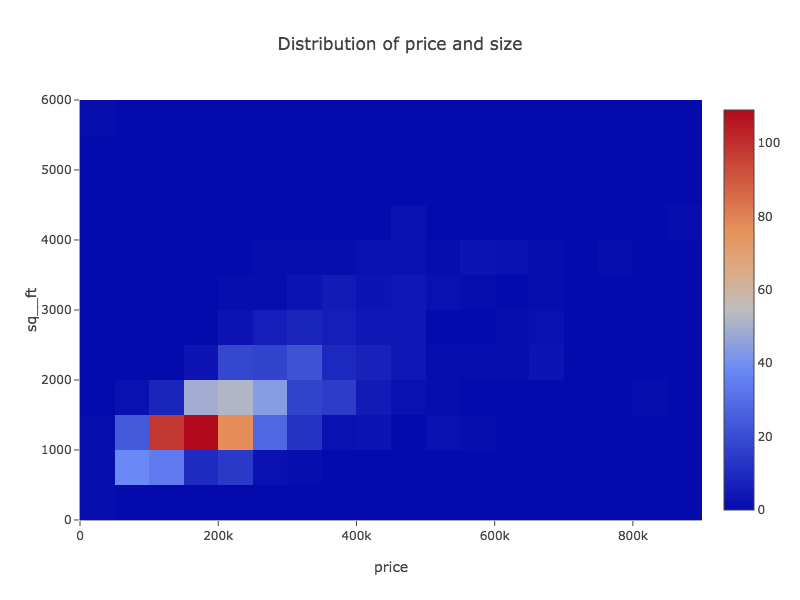
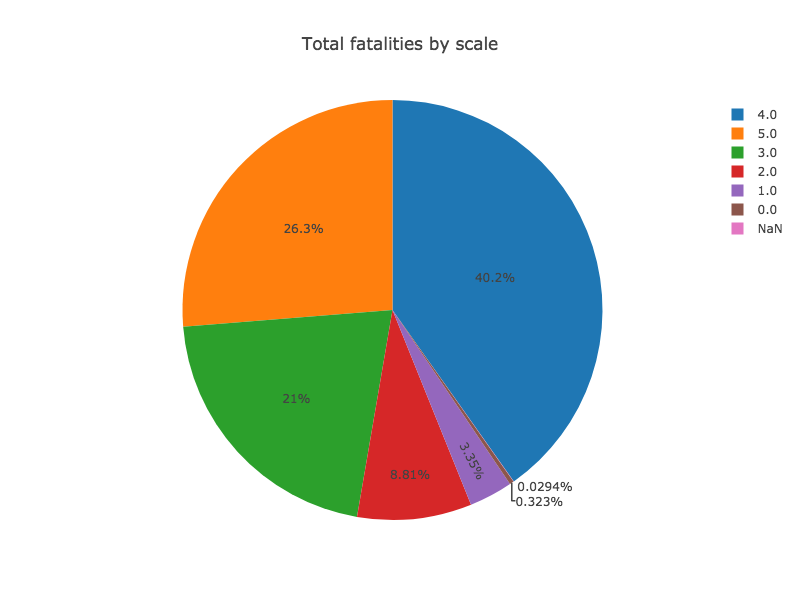
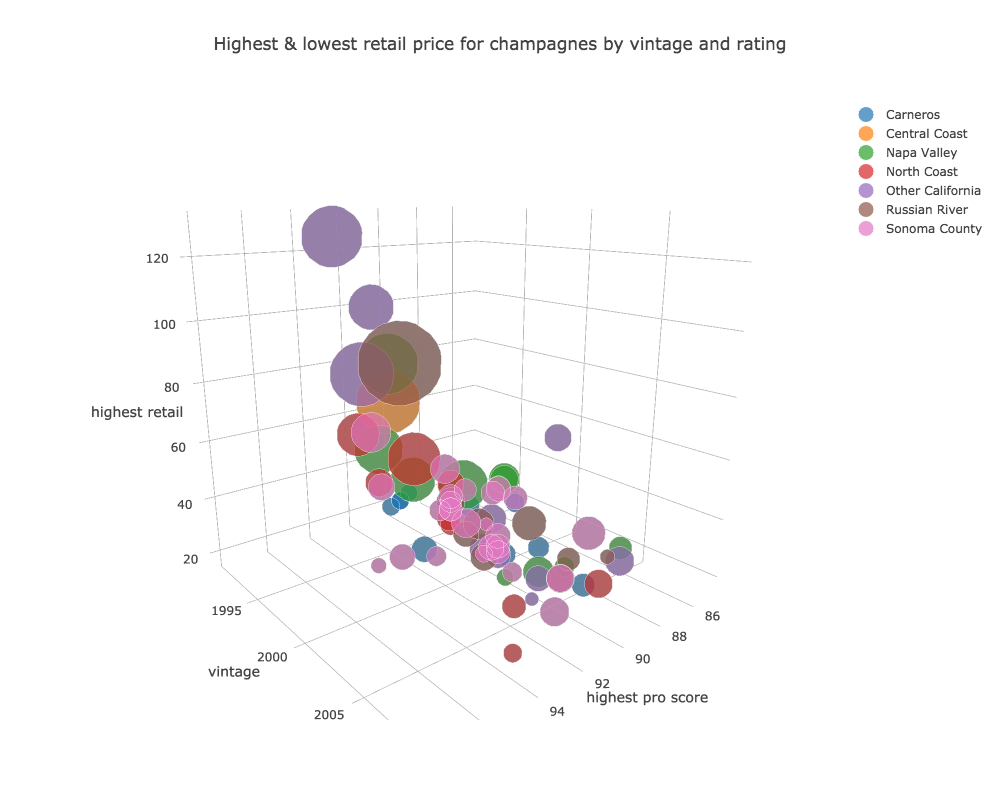
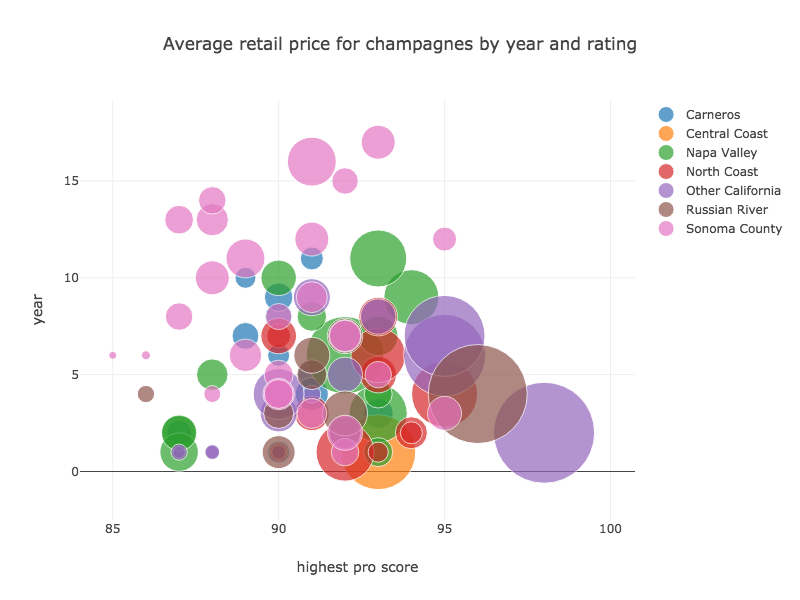
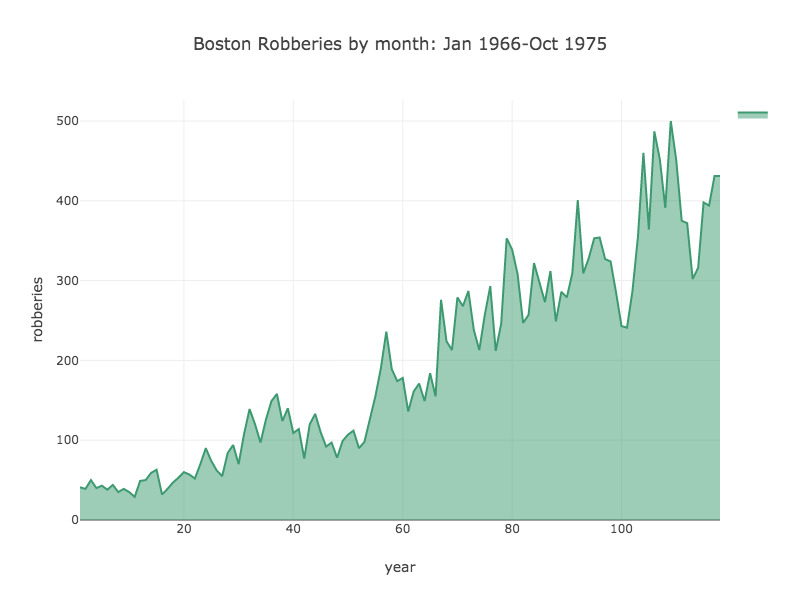
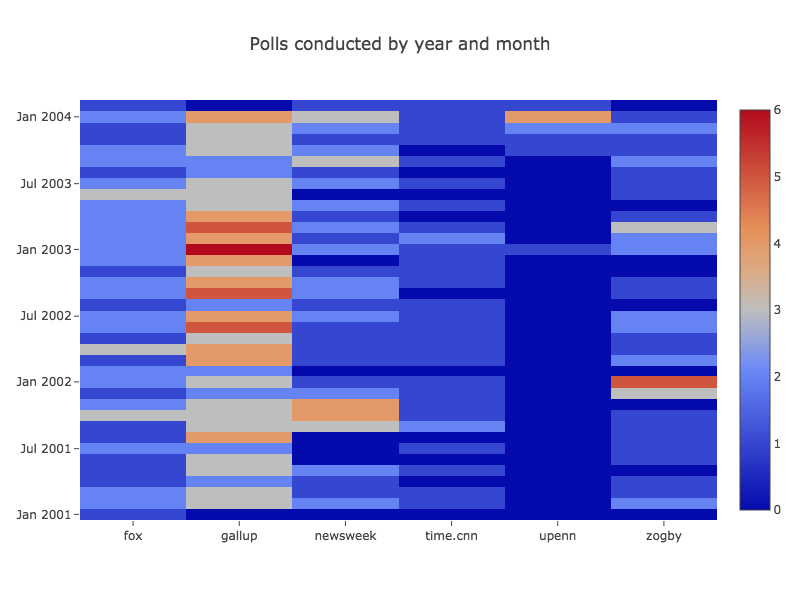
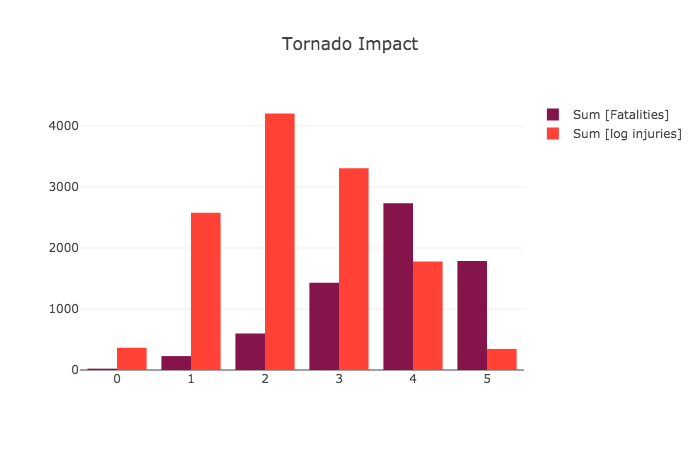
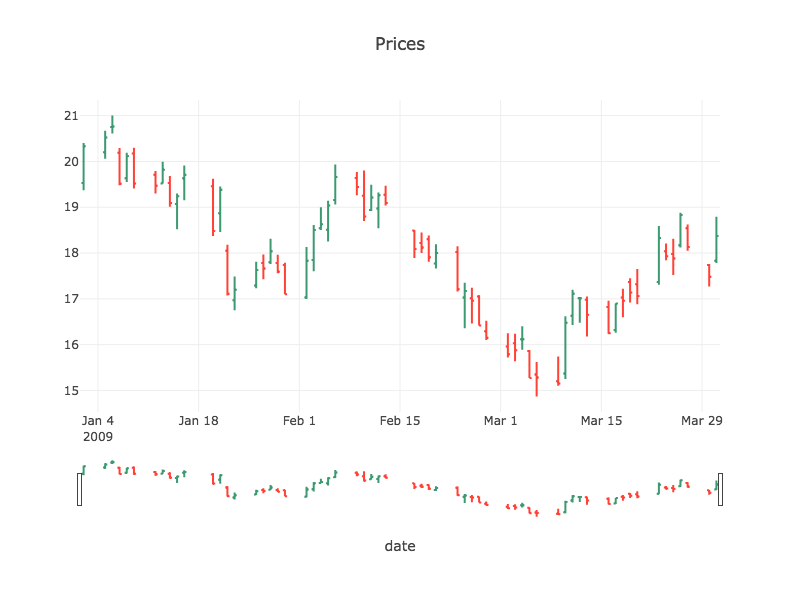
Tablesaw supports data visualization by providing a wrapper for the Plot.ly JavaScript plotting library. Here are a few examples of the new library in action.
 |
 |
 |
|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
Statistics
- Descriptive stats: mean, min, max, median, sum, product, standard deviation, variance, percentiles, geometric mean, skewness, kurtosis, etc.
Getting started
Add tablesaw-core to your project. You can find the version number for the latest release in the release notes:
<dependency>
<groupId>tech.tablesaw</groupId>
<artifactId>tablesaw-core</artifactId>
<version>VERSION_NUMBER_GOES_HERE</version>
</dependency>
You may also add supporting projects:
tablesaw-beakerx- for using Tablesaw inside BeakerXtablesaw-excel- for using Excel workbookstablesaw-html- for using HTMLtablesaw-json- for using JSONtablesaw-jsplot- for creating charts
Documentation and support
- Start here: https://jtablesaw.github.io/tablesaw/gettingstarted
- Then see our documentation page: https://jtablesaw.github.io/tablesaw/ and the Tablesaw User Guide.
And always feel free to ask questions or make suggestions here on the issues tab.
Integrations
- We recommend trying Tablesaw inside Jupyter notebooks, which lets you experiment with Tablesaw in a more interactive manner. Get started by installing BeakerX and trying the sample Tablesaw notebook
- You may utilize Tablesaw with many machine learning libraries. To see an example of using Tablesaw with Smile check out the sample Tablesaw Jupyter notebook
- You may use quandl4j-tablesaw if you'd like to load financial and economic data from Quandl into Tablesaw. This is demonstrated in the sample Tablesaw notebook as well















 96 Sep 27, 2022
96 Sep 27, 2022
 1.3k Dec 26, 2022
1.3k Dec 26, 2022
 386 Jan 2, 2023
386 Jan 2, 2023
 103 Nov 19, 2022
103 Nov 19, 2022
 226 Dec 20, 2022
226 Dec 20, 2022
 111 Aug 14, 2022
111 Aug 14, 2022
 1 Jan 8, 2022
1 Jan 8, 2022
 57 Nov 19, 2022
57 Nov 19, 2022
 16 Aug 23, 2020
16 Aug 23, 2020
 274 Dec 29, 2022
274 Dec 29, 2022
 171 Dec 31, 2022
171 Dec 31, 2022
 1.3k Jan 8, 2023
1.3k Jan 8, 2023
 1.2k Dec 31, 2022
1.2k Dec 31, 2022
 34 Sep 13, 2022
34 Sep 13, 2022
 184 Dec 28, 2022
184 Dec 28, 2022
 40 Dec 6, 2022
40 Dec 6, 2022
 1 Feb 13, 2022
1 Feb 13, 2022
 5 Jul 28, 2022
5 Jul 28, 2022
 1.4k Dec 29, 2022
1.4k Dec 29, 2022
 16.6k Dec 30, 2022
16.6k Dec 30, 2022