



Warp 10 Platform
Introduction
Warp 10 is an Open Source Geo Time Series Platform designed to handle data coming from sensors, monitoring systems and the Internet of Things.
Geo Time Series extend the notion of Time Series by merging the sequence of sensor readings with the sequence of sensor locations.
If your data have no location information, Warp 10 will handle them as regular Time Series.
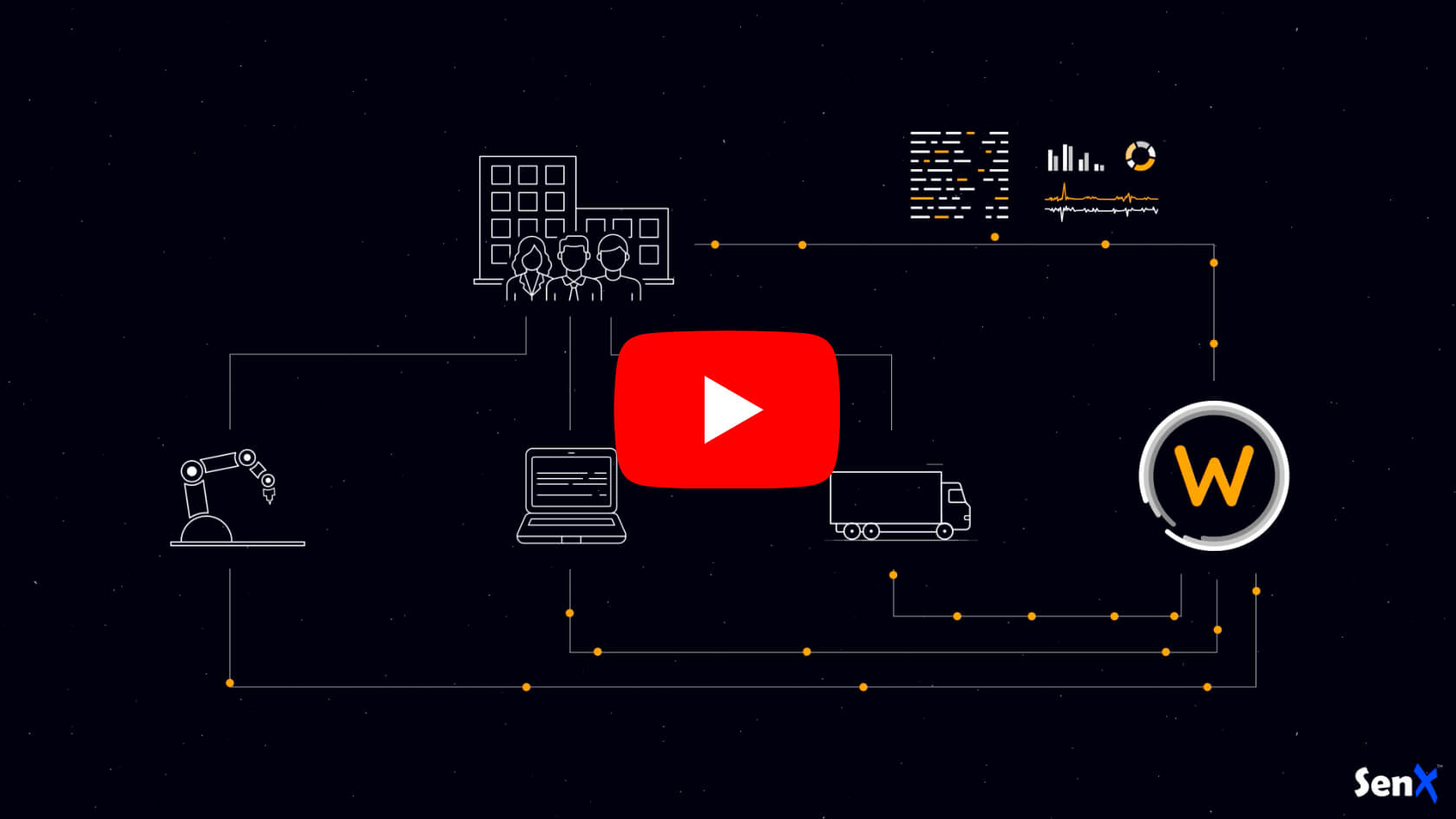
Features
The Warp 10 Platform provides a rich set of features to simplify your work around sensor data:
- Warp 10 Storage Engine, our collection and storage layer, a Geo Time Series Database
- WarpLib, a library dedicated to sensor data analysis with more than 1000 functions and extension capabilities
- WarpScript, a language specifically designed for analytics of time series data. It is one of the pillars of the analytics layer of the Warp 10 Platform
- FLoWS, an alternative to WarpScript for users discovering the Warp 10 Platform. It is meant to be easy to learn, look familiar to users of other programming languages and enable time series analysis by leveraging the whole of WarpLib.
- Plasma and Mobius, streaming engines allowing to cascade the Warp 10 Platform with Complex Event Processing solutions and to build dynamic dashboards
- Runner, a system for scheduling WarpScript program executions on the server side
- Sensision, a framework for exposing metrics and pushing them into Warp 10
- Standalone version running on a Raspberry Pi as well as on a beefy server, with no external dependencies
- Replication and sharding of standalone instances using the Datalog mechanism
- Distributed version, based on Hadoop HBase for the most demanding environments
- Integration with Pig, Spark, Flink, NiFi, Kafka Streams and Storm for batch and streaming analysis.
Getting started
We strongly recommend you to start with the getting started. You will learn the basics and the concepts behind Warp 10 step by step.
Learn more by browsing the documentation.
To test Warp 10 without installing it, try the free sandbox where you can get your hands on in no time.
Help & Community
The team has put lots of efforts into the documentation of the Warp 10 Platform, there are still some areas which may need improving, so we count on you to raise the overall quality.
We understand that discovering all the features of the Warp 10 Platform at once can be intimidating, that’s why you have several options to find answers to your questions:
- Explore the blog and especially the Tutorials and Thinking in WarpScript categories
- Explore the tutorials on warp10.io
- Follow us on Twitter
- Join the Lounge, the Warp 10 community on Slack
- Subscribe to the Google Group
- Ask your question on StackOverflow using warp10 and warpscript tags
- Get informed of the last news of the Platform thanks to the newsletter
Our goal is to build a large community of users to move our platform into territories we haven't explored yet and to make Warp 10 and WarpScript the standards for sensor data and the IoT.
Contributing to the Warp 10 Platform
Open source software is built by people like you, who spend their free time creating things the rest of the community can use.
You want to contribute to Warp 10? We encourage you to read the contributing page before.
Commercial Support
Should you need commercial support for your projects, SenX offers support plans which will give you access to the core team developing the platform.
Don't hesitate to contact us at [email protected] for all your enquiries.
Trademarks
Warp 10, WarpScript, WarpFleet, Geo Time Series and SenX are trademarks of SenX S.A.S.











 230 Dec 9, 2022
230 Dec 9, 2022
 842 Dec 20, 2022
842 Dec 20, 2022
 3k Jan 1, 2023
3k Jan 1, 2023
 1.7k Dec 17, 2022
1.7k Dec 17, 2022
 4.8k Dec 26, 2022
4.8k Dec 26, 2022
 9.9k Jan 1, 2023
9.9k Jan 1, 2023
 367 Oct 11, 2022
367 Oct 11, 2022
 286 Dec 7, 2022
286 Dec 7, 2022
 46.3k Jan 10, 2023
46.3k Jan 10, 2023
 4.5k Dec 30, 2022
4.5k Dec 30, 2022
 3.6k Jan 2, 2023
3.6k Jan 2, 2023
 4 Dec 28, 2022
4 Dec 28, 2022
 363 Dec 30, 2022
363 Dec 30, 2022
 1 Sep 12, 2022
1 Sep 12, 2022
 495 Dec 1, 2022
495 Dec 1, 2022
 146 Dec 20, 2022
146 Dec 20, 2022
 1.2k Dec 27, 2022
1.2k Dec 27, 2022
 613 Dec 17, 2022
613 Dec 17, 2022
 3 Nov 8, 2022
3 Nov 8, 2022