ElasticJob - distributed scheduled job solution
Official website: https://shardingsphere.apache.org/elasticjob/

ElasticJob is a distributed scheduling solution consisting of two separate projects, ElasticJob-Lite and ElasticJob-Cloud.
Through the functions of flexible scheduling, resource management and job management, it creates a distributed scheduling solution suitable for Internet scenarios, and provides a diversified job ecosystem through open architecture design. It uses a unified job API for each project. Developers only need code one time and can deploy at will.
ElasticJob became an Apache ShardingSphere Sub-project on May 28 2020.
Welcome communicate with community via mail list.



Introduction
Using ElasticJob can make developers no longer worry about the non functional requirements such as jobs scale out, so that they can focus more on business coding; At the same time, it can release operators too, so that they do not have to worry about jobs high availability and management, and can automatic operation by simply adding servers.
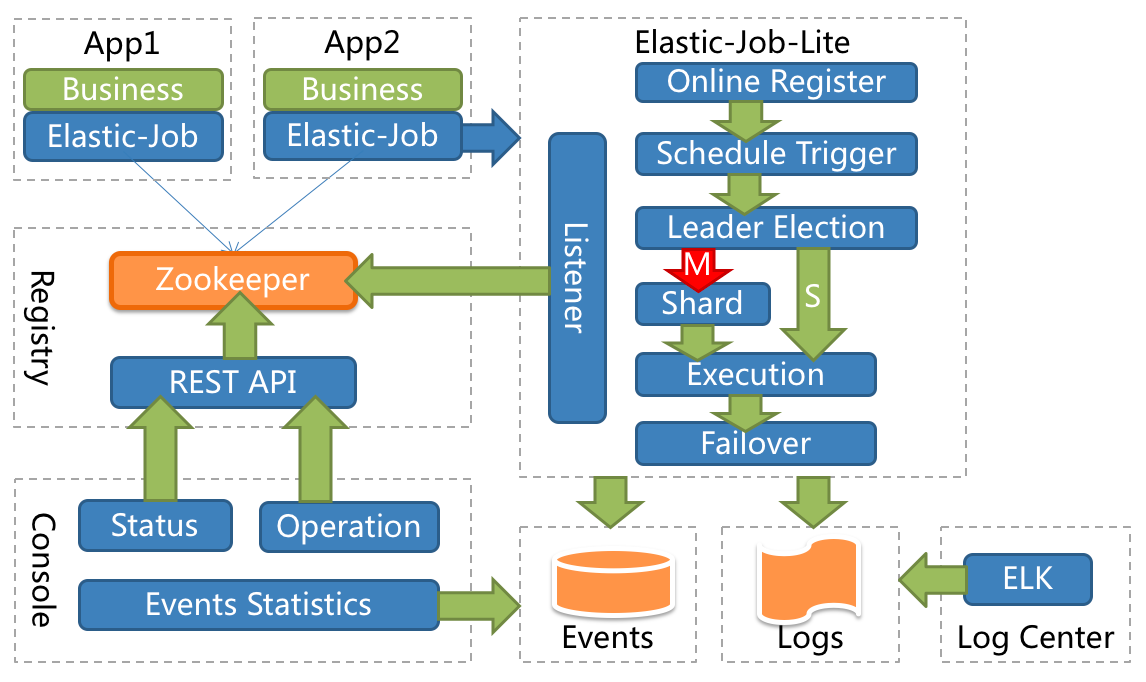
ElasticJob-Lite
A lightweight, decentralized solution that provides distributed task sharding services.
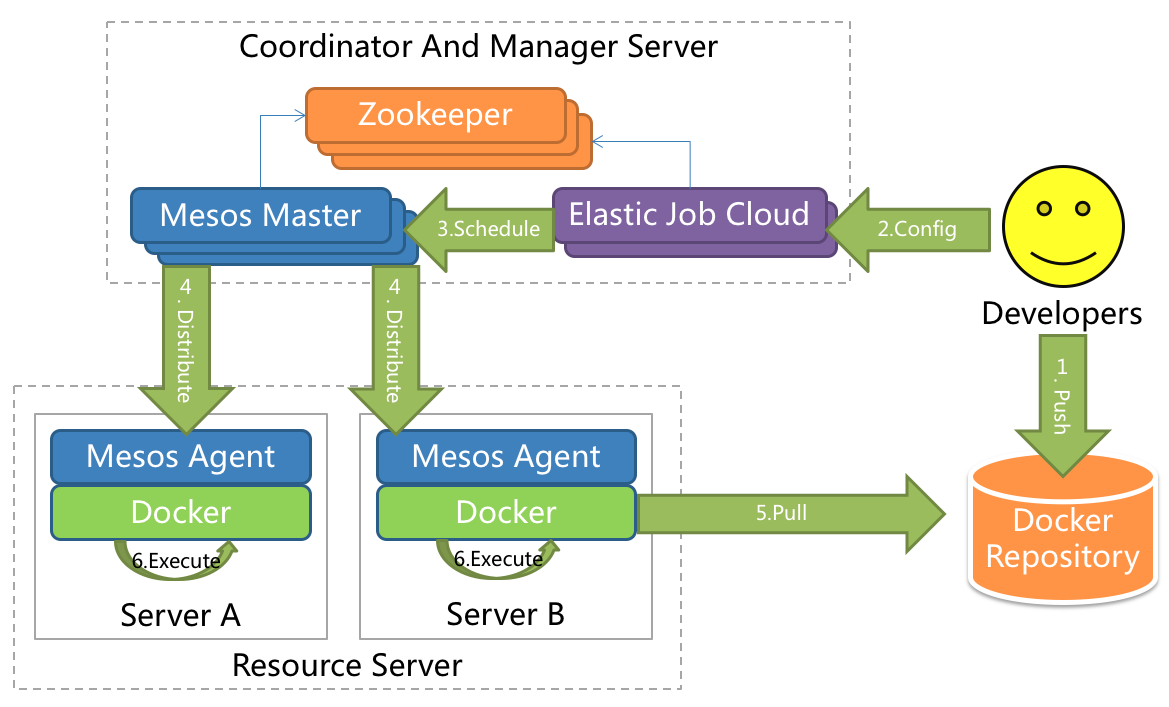
ElasticJob-Cloud
Uses Mesos to manage and isolate resources.
| ElasticJob-Lite | ElasticJob-Cloud | |
|---|---|---|
| Decentralization | Yes | No |
| Resource Assign | No | Yes |
| Job Execution | Daemon | Daemon + Transient |
| Deploy Dependency | ZooKeeper | ZooKeeper + Mesos |
Features
-
Elastic Schedule
- Support job sharding and high availability in distributed system
- Scale out for throughput and efficiency improvement
- Job processing capacity is flexible and scalable with the allocation of resources
-
Resource Assign
- Execute job on suitable time and assigned resources
- Aggregation same job to same job executor
- Append resources to newly assigned jobs dynamically
-
Job Governance
- Failover
- Misfired
- Self diagnose and recover when distribute environment unstable
-
Job Dependency (TODO)
- DAG based job dependency
- DAG based job item dependency
-
Job Open Ecosystem
- Unify job api for extension
- Support rich job type lib, such as dataflow, script, HTTP, file, big data
- Focus business SDK, can work with Spring IOC
-
- Job administration
- Job event trace query
- Registry center management
Environment Required
Java
Java 8 or above required.
Maven
Maven 3.5.0 or above required.
ZooKeeper
ZooKeeper 3.6.0 or above required. See details
Mesos (ElasticJob-Cloud only)
Mesos 1.1.0 or compatible version required (For ElasticJob-Cloud only). See details











![[ISSUE #2142]add distributed lock to avoid onceListener invoke multi times](https://avatars.githubusercontent.com/u/25291149?v=4)






 262 Dec 9, 2022
262 Dec 9, 2022
 23.3k Jan 9, 2023
23.3k Jan 9, 2023
 571 Dec 29, 2022
571 Dec 29, 2022
 2.8k Jan 7, 2023
2.8k Jan 7, 2023
 73 Dec 26, 2022
73 Dec 26, 2022
 676 Dec 30, 2022
676 Dec 30, 2022
 8.9k Dec 26, 2022
8.9k Dec 26, 2022
 1k Jan 1, 2023
1k Jan 1, 2023
 2.3k Dec 29, 2022
2.3k Dec 29, 2022
 1.7k Dec 28, 2022
1.7k Dec 28, 2022
 2.1k Jan 4, 2023
2.1k Jan 4, 2023
 1.9k Jan 3, 2023
1.9k Jan 3, 2023
 34 Oct 14, 2022
34 Oct 14, 2022
 911 Dec 9, 2022
911 Dec 9, 2022
 41 Dec 30, 2022
41 Dec 30, 2022
 544 Nov 23, 2022
544 Nov 23, 2022
 5.7k Dec 29, 2022
5.7k Dec 29, 2022