292 Repositories
Java data-analytics Libraries
Generate Java types from JSON or JSON Schema and annotates those types for data-binding with Jackson, Gson, etc
jsonschema2pojo jsonschema2pojo generates Java types from JSON Schema (or example JSON) and can annotate those types for data-binding with Jackson 2.x
Apache Camel is an open source integration framework that empowers you to quickly and easily integrate various systems consuming or producing data.
Apache Camel Apache Camel is a powerful, open-source integration framework based on prevalent Enterprise Integration Patterns with powerful bean integ
Spring,SpringBoot 2.0,SpringMVC,Mybatis,mybatis-plus,motan/dubbo分布式,Redis缓存,Shiro权限管理,Spring-Session单点登录,Quartz分布式集群调度,Restful服务,QQ/微信登录,App token登录,微信/支付宝支付;日期转换、数据类型转换、序列化、汉字转拼音、身份证号码验证、数字转人民币、发送短信、发送邮件、加密解密、图片处理、excel导入导出、FTP/SFTP/fastDFS上传下载、二维码、XML读写、高精度计算、系统配置工具类等等。
iBase4J项目简介 iBase4J是Java语言的分布式系统架构。 使用Spring整合开源框架。 使用Maven对项目进行模块化管理,提高项目的易开发性、扩展性。 系统包括4个子系统:系统管理Service、系统管理Web、业务Service、业务Web。 系统管理:包括用户管理、权限管理、数
:herb: 基于springboot的快速学习示例,整合自己遇到的开源框架,如:rabbitmq(延迟队列)、Kafka、jpa、redies、oauth2、swagger、jsp、docker、spring-batch、异常处理、日志输出、多模块开发、多环境打包、缓存cache、爬虫、jwt、GraphQL、dubbo、zookeeper和Async等等:pushpin:
欢迎大家留言和PR~ Tip: 技术更新换代太快,本仓库仅做参考,自己的项目具体使用哪个版本还需谨慎思考~(不推荐使用最新的版本,推荐使用(最新-1|2)的版本,会比较稳定) spring-boot-quick 前言 自己很早就想搞一个总的仓库就是将自己平时遇到的和学习到的东西整合在一起,方便后
Not only Spring Boot but also important knowledge of Spring(不只是SpringBoot还有Spring重要知识点)
在线阅读 : https://snailclimb.gitee.io/springboot-guide (上面的地址访问速度缓慢的建议使用这个路径访问) 重要知识点 基础 Spring Boot 介绍 第一个 Hello World 第一个 RestFul Web 服务 Spring 如何优雅读取配
Spring Boot基础教程,Spring Boot 2.x版本连载中!!!

Spring Boot基础教程 本项目内容为《Spring Boot基础教程》的程序样例。 专题目标:打造全网内容最全,比收费教程更好的Spring Boot免费教程! 加入社群:如果你正在学习Spring Boot,不妨加入我们的Spring技术交流群,一起成长! 如何支持: 关注我的公众号”程序
about learning Spring Boot via examples. Spring Boot 教程、技术栈示例代码,快速简单上手教程。
Spring Boot 学习示例 Spring Boot 使用的各种示例,以最简单、最实用为标准,此开源项目中的每个示例都以最小依赖,最简单为标准,帮助初学者快速掌握 Spring Boot 各组件的使用。 Spring Boot 中文索引 | Spring Cloud学习示例代码 | Spring
云收藏 Spring Boot 2.X 开源项目
云收藏 - 让收藏更简单 云收藏是一个使用 Spring Boot 构建的开源网站,可以让用户在线随时随地收藏的一个网站,在网站上分类整理收藏的网站或者文章,可以作为稍后阅读的一个临时存放。作为一个开放开源的软件,可以让用户从浏览器将收藏夹内容导入到云收藏,也支持随时将云收藏收集的文章导出去做备份。
A 3D chart library for Java applications (JavaFX, Swing or server-side).
Orson Charts (C)opyright 2013-2020, by Object Refinery Limited. All rights reserved. Version 2.0, 15 March 2020. Overview Orson Charts is a 3D chart l
Kubed - A port of the popular Javascript library D3.js to Kotlin/JavaFX.
Kubed: A Kotlin DSL for data visualization Kubed is a data visualization DSL embedded within the Kotlin programming language. Kubed facilitates the cr
A scientific charting library focused on performance optimised real-time data visualisation at 25 Hz update rates for data sets with a few 10 thousand up to 5 million data points.

ChartFx ChartFx is a scientific charting library developed at GSI for FAIR with focus on performance optimised real-time data visualisation at 25 Hz u
A platform for visualization and real-time monitoring of data workflows

Status This project is no longer maintained. Ambrose Twitter Ambrose is a platform for visualization and real-time monitoring of MapReduce data workfl
The official home of the Presto distributed SQL query engine for big data
Presto Presto is a distributed SQL query engine for big data. See the User Manual for deployment instructions and end user documentation. Requirements
:elephant: Elasticsearch real-time search and analytics natively integrated with Hadoop
Elasticsearch Hadoop Elasticsearch real-time search and analytics natively integrated with Hadoop. Supports Map/Reduce, Apache Hive, Apache Pig, Apach
Apache Hive
Apache Hive (TM) The Apache Hive (TM) data warehouse software facilitates reading, writing, and managing large datasets residing in distributed storag
Apache Druid: a high performance real-time analytics database.
Website | Documentation | Developer Mailing List | User Mailing List | Slack | Twitter | Download Apache Druid Druid is a high performance real-time a
SAMOA (Scalable Advanced Massive Online Analysis) is an open-source platform for mining big data streams.
SAMOA: Scalable Advanced Massive Online Analysis. This repository is discontinued. The development of SAMOA has moved over to the Apache Software Foun
Apache Flink
Apache Flink Apache Flink is an open source stream processing framework with powerful stream- and batch-processing capabilities. Learn more about Flin
A distributed data integration framework that simplifies common aspects of big data integration such as data ingestion, replication, organization and lifecycle management for both streaming and batch data ecosystems.
Apache Gobblin Apache Gobblin is a highly scalable data management solution for structured and byte-oriented data in heterogeneous data ecosystems. Ca
Hadoop library for large-scale data processing, now an Apache Incubator project
Apache DataFu Follow @apachedatafu Apache DataFu is a collection of libraries for working with large-scale data in Hadoop. The project was inspired by
Mirror of Apache Storm
Master Branch: Storm is a distributed realtime computation system. Similar to how Hadoop provides a set of general primitives for doing batch processi
Netflix's distributed Data Pipeline
Suro: Netflix's Data Pipeline Suro is a data pipeline service for collecting, aggregating, and dispatching large volume of application events includin
Web-based notebook that enables data-driven, interactive data analytics and collaborative documents with SQL, Scala and more.
Apache Zeppelin Documentation: User Guide Mailing Lists: User and Dev mailing list Continuous Integration: Contributing: Contribution Guide Issue Trac
OpenRefine is a free, open source power tool for working with messy data and improving it
OpenRefine OpenRefine is a Java-based power tool that allows you to load data, understand it, clean it up, reconcile it, and augment it with data comi
Serverless proxy for Spark cluster
Hydrosphere Mist Hydrosphere Mist is a serverless proxy for Spark cluster. Mist provides a new functional programming framework and deployment model f
H2O is an Open Source, Distributed, Fast & Scalable Machine Learning Platform: Deep Learning, Gradient Boosting (GBM) & XGBoost, Random Forest, Generalized Linear Modeling (GLM with Elastic Net), K-Means, PCA, Generalized Additive Models (GAM), RuleFit, Support Vector Machine (SVM), Stacked Ensembles, Automatic Machine Learning (AutoML), etc.
H2O H2O is an in-memory platform for distributed, scalable machine learning. H2O uses familiar interfaces like R, Python, Scala, Java, JSON and the Fl
statistics, data mining and machine learning toolbox
Disambiguation (Italian dictionary) Field of turnips. It is also a place where there is confusion, where tricks and sims are plotted. (Computer scienc
Encog java core Apache 2 Encog java core Encog is an advanced machine learning framework that supports a variety of advanced algorithms, as well as support classes to normalize and process data. Machine learning algorithms such as Support Vector Machines, Artificial Neural Networks, Genetic Programming, Bayesian Networks, Hidden Markov Models, Genetic Programming and Genetic Algorithms are supported. License: Apache 2 , .
Encog Machine Learning Framework Encog is a pure-Java/C# machine learning framework that I created back in 2008 to support genetic programming, NEAT/H
Sends stacktrace-level performance data from a JVM process to Riemann.

Riemann JVM Profiler riemann-jvm-profiler is a JVM agent that you can inject into any JVM process--one written in Clojure, Java, Scala, Groovy, etc.--
GoReplay is an open-source tool for capturing and replaying live HTTP traffic into a test environment in order to continuously test your system with real data. It can be used to increase confidence in code deployments, configuration changes and infrastructure changes.
https://goreplay.org/ GoReplay is an open-source network monitoring tool which can record your live traffic, and use it for shadowing, load testing, m
Java 8 annotation processor and framework for deriving algebraic data types constructors, pattern-matching, folds, optics and typeclasses.
Derive4J: Java 8 annotation processor for deriving algebraic data types constructors, pattern matching and more! tl;dr Show me how to write, say, the
NoSQL data store using the seastar framework, compatible with Apache Cassandra
Scylla What is Scylla? Scylla is the real-time big data database that is API-compatible with Apache Cassandra and Amazon DynamoDB. Scylla embraces a s
Apache Druid: a high performance real-time analytics database.
Website | Documentation | Developer Mailing List | User Mailing List | Slack | Twitter | Download Apache Druid Druid is a high performance real-time a
Eclipse Collections is a collections framework for Java with optimized data structures and a rich, functional and fluent API.
English | 中文 | Deutsch | Español | Ελληνικά | Français | 日本語 | Norsk (bokmål) | Português-Brasil | Русский | हिंदी Eclipse Collections is a comprehens
An advanced, but easy to use, platform for writing functional applications in Java 8.
Getting Cyclops X (10) The latest version is cyclops:10.4.0 Stackoverflow tag cyclops-react Documentation (work in progress for Cyclops X) Integration
binary serialization format
Colfer Colfer is a binary serialization format optimized for speed and size. The project's compiler colf(1) generates source code from schema definiti
Clojure's data structures modified for use outside of Clojure
This library has been extracted from the master branch of Clojure (http://clojure.org) version 1.5.1 (as of October 2013) http://github.com/richhick
High Performance data structures and utility methods for Java
Agrona Agrona provides a library of data structures and utility methods that are a common need when building high-performance applications in Java. Ma
jdbi is designed to provide convenient tabular data access in Java; including templated SQL, parameterized and strongly typed queries, and Streams integration
The Jdbi library provides convenient, idiomatic access to relational databases in Java. Jdbi is built on top of JDBC. If your database has a JDBC driv
A distributed in-memory data store for the cloud
EVCache EVCache is a memcached & spymemcached based caching solution that is mainly used for AWS EC2 infrastructure for caching frequently used data.
CrateDB is a distributed SQL database that makes it simple to store and analyze massive amounts of machine data in real-time.
About CrateDB is a distributed SQL database that makes it simple to store and analyze massive amounts of machine data in real-time. CrateDB offers the
Apache Hive
Apache Hive (TM) The Apache Hive (TM) data warehouse software facilitates reading, writing, and managing large datasets residing in distributed storag
The official home of the Presto distributed SQL query engine for big data
Presto Presto is a distributed SQL query engine for big data. See the User Manual for deployment instructions and end user documentation. Requirements
Distributed Stream and Batch Processing

What is Jet Jet is an open-source, in-memory, distributed batch and stream processing engine. You can use it to process large volumes of real-time eve
Mirror of Apache Storm
Master Branch: Storm is a distributed realtime computation system. Similar to how Hadoop provides a set of general primitives for doing batch processi
Redisson - Redis Java client with features of In-Memory Data Grid. Over 50 Redis based Java objects and services: Set, Multimap, SortedSet, Map, List, Queue, Deque, Semaphore, Lock, AtomicLong, Map Reduce, Publish / Subscribe, Bloom filter, Spring Cache, Tomcat, Scheduler, JCache API, Hibernate, MyBatis, RPC, local cache ...
Redisson - Redis Java client with features of In-Memory Data Grid Quick start | Documentation | Javadocs | Changelog | Code examples | FAQs | Report a
Utility for developers and QAs what helps minimize time wasting on writing the same data for testing over and over again. Made by Stfalcon
Stfalcon Fixturer A Utility for developers and QAs which helps minimize time wasting on writing the same data for testing over and over again. You can
Gephi - The Open Graph Viz Platform
Gephi - The Open Graph Viz Platform Gephi is an award-winning open-source platform for visualizing and manipulating large graphs. It runs on Windows,
Embulk: Pluggable Bulk Data Loader.

What's Embulk? Embulk is a parallel bulk data loader that helps data transfer between various storages, databases, NoSQL and cloud services. Embulk su
Dex : The Data Explorer -- A data visualization tool written in Java/Groovy/JavaFX capable of powerful ETL and publishing web visualizations.

Dex Dex : The data explorer is a powerful tool for data science. It is written in Groovy and Java on top of JavaFX and offers the ability to: Read in
Java fake data generator
jFairy by Devskiller Java fake data generator. Based on Wikipedia: Fairyland, in folklore, is the fabulous land or abode of fairies or fays. Try jFair
A library for setting up Java objects as test data.
Beanmother Beanmother helps to create various objects, simple and complex, super easily with fixtures for testing. It encourages developers to write m
Easy to use cryptographic framework for data protection: secure messaging with forward secrecy and secure data storage. Has unified APIs across 14 platforms.
Themis provides strong, usable cryptography for busy people General purpose cryptographic library for storage and messaging for iOS (Swift, Obj-C), An
XChart is a light-weight Java library for plotting data.
XChart XChart is a light weight Java library for plotting data. Description XChart is a light-weight and convenient library for plotting data designed
Java dataframe and visualization library
Tablesaw Overview Tablesaw is Java for data science. It includes a dataframe and a visualization library, as well as utilities for loading, transformi
A 3D chart library for Java applications (JavaFX, Swing or server-side).
Orson Charts (C)opyright 2013-2020, by Object Refinery Limited. All rights reserved. Version 2.0, 15 March 2020. Overview Orson Charts is a 3D chart l
The foundational library of the Morpheus data science framework
Introduction The Morpheus library is designed to facilitate the development of high performance analytical software involving large datasets for both
Master repository for the JGraphT project
JGraphT Released: June 14, 2020 Written by Barak Naveh and Contributors (C) Copyright 2003-2020, by Barak Naveh and Contributors. All rights reserved.
A scientific charting library focused on performance optimised real-time data visualisation at 25 Hz update rates for data sets with a few 10 thousand up to 5 million data points.
ChartFx ChartFx is a scientific charting library developed at GSI for FAIR with focus on performance optimised real-time data visualisation at 25 Hz u
Library for OpenAPI 3 with spring-boot
Full documentation Acknowledgements springdoc-openapi is made possible thanks to all of its contributors. Introduction The springdoc-openapi Java libr
CogComp's Natural Language Processing libraries and Demos:
CogCompNLP This project collects a number of core libraries for Natural Language Processing (NLP) developed by Cognitive Computation Group. How to use
An extensible Java framework for building XML and non-XML streaming applications
Smooks Framework This is the Git source code repository for the Smooks Project. Build Status Building Pre-requisites JDK 8 Apache Maven 3.2.x Maven gi
Apache Camel is an open source integration framework that empowers you to quickly and easily integrate various systems consuming or producing data.
Apache Camel Apache Camel is a powerful, open-source integration framework based on prevalent Enterprise Integration Patterns with powerful bean integ
A distributed event bus that implements a RESTful API abstraction on top of Kafka-like queues

Nakadi Event Broker Nakadi is a distributed event bus broker that implements a RESTful API abstraction on top of Kafka-like queues, which can be used
Datumbox is an open-source Machine Learning framework written in Java which allows the rapid development of Machine Learning and Statistical applications.
Datumbox Machine Learning Framework The Datumbox Machine Learning Framework is an open-source framework written in Java which allows the rapid develop
Apache Flink
Apache Flink Apache Flink is an open source stream processing framework with powerful stream- and batch-processing capabilities. Learn more about Flin
Apache Spark - A unified analytics engine for large-scale data processing
Apache Spark Spark is a unified analytics engine for large-scale data processing. It provides high-level APIs in Scala, Java, Python, and R, and an op
Statistical Machine Intelligence & Learning Engine
Smile Smile (Statistical Machine Intelligence and Learning Engine) is a fast and comprehensive machine learning, NLP, linear algebra, graph, interpola
Stream Processing and Complex Event Processing Engine
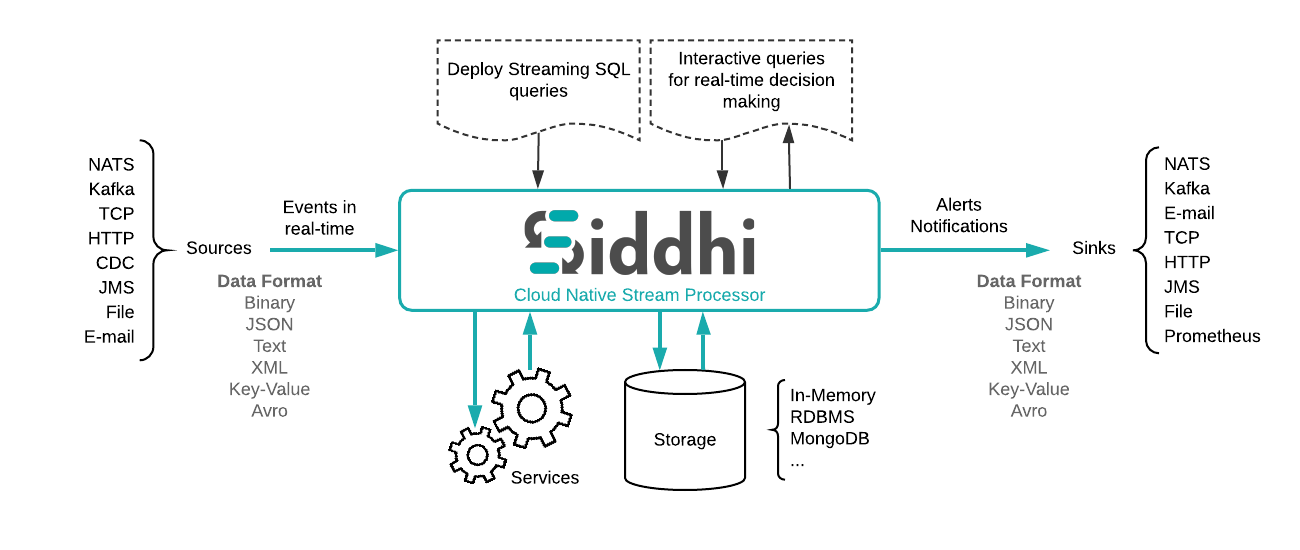
Siddhi Core Libraries Siddhi is a cloud native Streaming and Complex Event Processing engine that understands Streaming SQL queries in order to captur
Logstash - transport and process your logs, events, or other data
Logstash Logstash is part of the Elastic Stack along with Beats, Elasticsearch and Kibana. Logstash is a server-side data processing pipeline that ing
P6Spy is a framework that enables database data to be seamlessly intercepted and logged with no code changes to the application.
p6spy P6Spy is a framework that enables database data to be seamlessly intercepted and logged with no code changes to existing application. The P6Spy
JCTools - Concurrency tools currently missing from the JDK.
JCTools Java Concurrency Tools for the JVM. This project aims to offer some concurrent data structures currently missing from the JDK: SPSC/MPSC/SPMC/
Eclipse Collections is a collections framework for Java with optimized data structures and a rich, functional and fluent API.
English | 中文 | Deutsch | Español | Ελληνικά | Français | 日本語 | Norsk (bokmål) | Português-Brasil | Русский | हिंदी Eclipse Collections is a comprehens
High Performance data structures and utility methods for Java
Agrona Agrona provides a library of data structures and utility methods that are a common need when building high-performance applications in Java. Ma
Functional patterns for Java
λ Functional patterns for Java Table of Contents Background Installation Examples Semigroups Monoids Functors Bifunctors Profunctors Applicatives Mona
Java 8 annotation processor and framework for deriving algebraic data types constructors, pattern-matching, folds, optics and typeclasses.
Derive4J: Java 8 annotation processor for deriving algebraic data types constructors, pattern matching and more! tl;dr Show me how to write, say, the
An advanced, but easy to use, platform for writing functional applications in Java 8.
Getting Cyclops X (10) The latest version is cyclops:10.4.0 Stackoverflow tag cyclops-react Documentation (work in progress for Cyclops X) Integration
:fire: Seata is an easy-to-use, high-performance, open source distributed transaction solution.

Seata: Simple Extensible Autonomous Transaction Architecture What is Seata? A distributed transaction solution with high performance and ease of use f
Open Source In-Memory Data Grid
Hazelcast Hazelcast is an open-source distributed in-memory data store and computation platform. It provides a wide variety of distributed data struct
A reactive Java framework for building fault-tolerant distributed systems
Atomix Website | Javadoc | Slack | Google Group A reactive Java framework for building fault-tolerant distributed systems Please see the website for f
A Java library for parsing and building iCalendar data models
iCal4j - iCalendar parser and object model Table of Contents Introduction - What is iCal4j? Setup - Download and installation of iCal4j System require
Redisson - Redis Java client with features of In-Memory Data Grid. Over 50 Redis based Java objects and services: Set, Multimap, SortedSet, Map, List, Queue, Deque, Semaphore, Lock, AtomicLong, Map Reduce, Publish / Subscribe, Bloom filter, Spring Cache, Tomcat, Scheduler, JCache API, Hibernate, MyBatis, RPC, local cache ...
Redisson - Redis Java client with features of In-Memory Data Grid Quick start | Documentation | Javadocs | Changelog | Code examples | FAQs | Report a
Official repository of Trino, the distributed SQL query engine for big data, formerly known as PrestoSQL (https://trino.io)

Trino is a fast distributed SQL query engine for big data analytics. See the User Manual for deployment instructions and end user documentation. Devel
Apache Druid: a high performance real-time analytics database.
Website | Documentation | Developer Mailing List | User Mailing List | Slack | Twitter | Download Apache Druid Druid is a high performance real-time a
Change data capture for a variety of databases. Please log issues at https://issues.redhat.com/browse/DBZ.
Copyright Debezium Authors. Licensed under the Apache License, Version 2.0. The Antlr grammars within the debezium-ddl-parser module are licensed unde
Apache Calcite
Apache Calcite Apache Calcite is a dynamic data management framework. It contains many of the pieces that comprise a typical database management syste
Apache ORC - the smallest, fastest columnar storage for Hadoop workloads
Apache ORC ORC is a self-describing type-aware columnar file format designed for Hadoop workloads. It is optimized for large streaming reads, but with
Protocol Buffers - Google's data interchange format
Protocol Buffers - Google's data interchange format Copyright 2008 Google Inc. https://developers.google.com/protocol-buffers/ Overview Protocol Buffe
adt4j - Algebraic Data Types for Java
adt4j - Algebraic Data Types for Java This library implements Algebraic Data Types for Java. ADT4J provides annotation processor for @GenerateValueCla
Infinispan is an open source data grid platform and highly scalable NoSQL cloud data store.
The Infinispan project Infinispan is an open source (under the Apache License, v2.0) data grid platform. For more information on Infinispan, including
cglib - Byte Code Generation Library is high level API to generate and transform Java byte code. It is used by AOP, testing, data access frameworks to generate dynamic proxy objects and intercept field access.
cglib Byte Code Generation Library is high level API to generate and transform JAVA byte code. It is used by AOP, testing, data access frameworks to g
Dozer is a Java Bean to Java Bean mapper that recursively copies data from one object to another.
Dozer Active Contributors We are always looking for more help. The below is the current active list: Core @garethahealy @orange-buffalo ?? Protobuf @j